这个
SELECT * FROM SOME_TABLE WHERE SOME_FIELD LIKE '%some_value%';
比这个慢
SELECT * FROM SOME_TABLE WHERE SOME_FIELD = 'some_value';
但是这个呢?
SELECT * FROM SOME_TABLE WHERE SOME_FIELD LIKE 'some_value';
我的测试表明第二个和第三个例子完全相同。如果是这样,那么我的问题是,为什么要使用"="?
这个
SELECT * FROM SOME_TABLE WHERE SOME_FIELD LIKE '%some_value%';
比这个慢
SELECT * FROM SOME_TABLE WHERE SOME_FIELD = 'some_value';
但是这个呢?
SELECT * FROM SOME_TABLE WHERE SOME_FIELD LIKE 'some_value';
我的测试表明第二个和第三个例子完全相同。如果是这样,那么我的问题是,为什么要使用"="?
如果你在 Oracle 中除了数据仓库或其他批量数据操作之外的任何操作中使用绑定变量,就会出现明显的差异。
举个例子:
SELECT * FROM SOME_TABLE WHERE SOME_FIELD LIKE :b1
Oracle不能在执行之前知道:b1的值是'%some_value%'、'some_value'等,因此它会根据启发式算法估计结果的基数,并提出一个适当的计划,这个计划可能适用于:b的各种值,如'%A'、'%'、'A'等。
使用等式谓词时可能存在类似的问题,但可能产生的基数范围更容易根据列统计信息或唯一约束的存在进行估计。
所以,个人认为我不会开始使用LIKE来替换=。有时优化器很容易被愚弄。
请查看执行计划。它们生成相同的执行计划,所以对于数据库来说,它们是相同的内容。
你应该使用=来测试等式,而不是相似性。如果你也控制比较值,那么差别不大。如果比较值由用户提交,则'apple'和'apple%'将给出非常不同的结果。
你尝试过吗?测试是唯一确保正确性的方法。
另外,这些语句中没有一个能够确保返回相同的行。可以尝试:
insert into some_table (some_field) values ('some_value');
insert into some_table (some_fieled) values ('1some_value2');
insert into some_table (some_field) values ('some1value');
SELECT * FROM SOME_TABLE WHERE SOME_FIELD LIKE '%some_value%';
SELECT * FROM SOME_TABLE WHERE SOME_FIELD = 'some_value';
SELECT * FROM SOME_TABLE WHERE SOME_FIELD LIKE 'some_value';
LIKE '%some_value%' 返回所有三条记录,= 'some_value' 只返回第二条记录,LIKE 'some_value' 返回第一条和第三条记录。 - Keith DaviesWHERE some_field = 'some_value'并不会像LIKE 'some_value'一样返回some1value,因为对于LIKE,下划线是任何字符的占位符。对于等号来说,它当然是一个字面值,因此不会返回该记录。试试看吧。 - Lemmes使用“LIKE'%WHATEVER%'”将不得不进行完整的索引扫描。
如果没有百分号,那么它的作用就像等于号。
如果%在一端,则索引可以是范围扫描。
我不确定优化器如何处理绑定字段。
like 如果没有像 $% 这样的字符,那么它在形式上是相同的,因此发现它具有相同的成本并不令人惊讶。
我认为David Aldridge的答案很有趣,因为您的应用程序应该使用绑定变量。使用 like '%foobar' 时,您无法利用索引中的排序。如果查询是预编译的,则会导致更多的索引或表全扫描。
此外,我认为这很危险,因为它可能导致SQL注入和奇怪的错误(例如,如果有一个名为john的用户,黑客可以创建一个名为'joh$' 的用户并尝试登录)
为什么要冒险呢?'=' 更清晰,而且没有这些问题。
1) %和=旨在用于不同的情况。即使我们可以在like子句中使用精确值进行搜索并获得所需结果,但在所有这样的情况下仍应该使用=。因此,每当我们有精确值要搜索时,我们总是应该使用=。
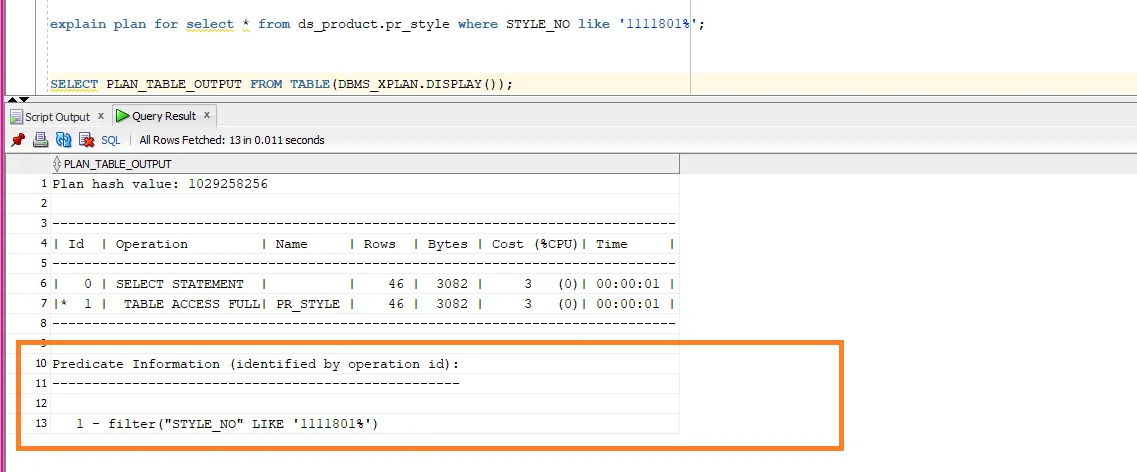
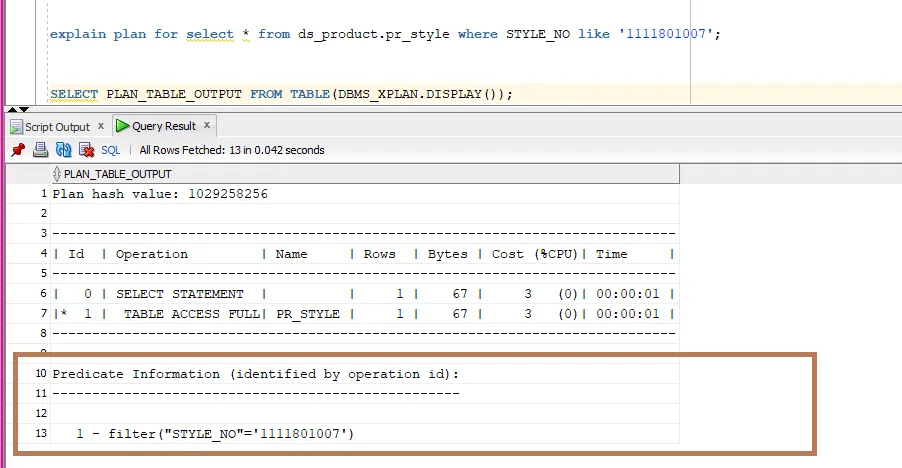
2) 当搜索子句中没有提供%时,like和=的性能: 在所有这些情况下,查询优化器会自动将like子句转换为=。这可以从查询计划中看到(请参见附加的屏幕截图)。因此,在这种情况下,性能应该完全相同。感谢查询优化器!
我提供了两个查询的执行计划的屏幕截图,即带有like子句但不含%的查询和带有like子句且包含%的查询。