我目前正在阅读安东尼·威廉姆斯的《C++ Concurrency in Action》。他的其中一段代码如下,并指出断言z != 0可能会触发。
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x()
{
x.store(true,std::memory_order_release);
}
void write_y()
{
y.store(true,std::memory_order_release);
}
void read_x_then_y()
{
while(!x.load(std::memory_order_acquire));
if(y.load(std::memory_order_acquire))
++z;
}
void read_y_then_x()
{
while(!y.load(std::memory_order_acquire));
if(x.load(std::memory_order_acquire))
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load()!=0);
}
我可以想到的不同执行路径如下:
1)
Thread a (x is now true)
Thread c (fails to increment z)
Thread b (y is now true)
Thread d (increments z) assertion cannot fire
2)
Thread b (y is now true)
Thread d (fails to increment z)
Thread a (x is now true)
Thread c (increments z) assertion cannot fire
3)
Thread a (x is true) Thread b (y is true) Thread c (z is incremented) assertion cannot fire Thread d (z is incremented)
有人能解释一下这个断言是如何触发的吗?
他展示了这个小图形: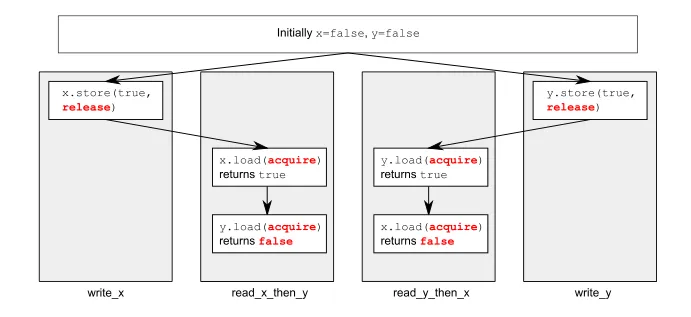
存储到y的操作是否也应该与read_x_then_y中的加载同步,存储到x的操作是否也应该与read_y_then_x中的加载同步?我很困惑。
编辑:
谢谢你们的回答,我理解原子操作的工作原理以及如何使用Acquire/Release。我只是不明白这个具体的例子。我试图弄清楚如果断言被触发,那么每个线程都做了什么?为什么如果我们使用顺序一致性,断言永远不会触发。
我的理解是,如果“线程a”(write_x)将x存储,则其已完成的所有工作都将与使用acquire顺序读取x的任何其他线程同步。一旦read_x_then_y看到这一点,它就会跳出循环并读取y。现在,有两种可能性。一种是write_y已经写入了y,这意味着此释放将与if语句(load)同步,这意味着z会增加,并且断言不会触发。另一种选择是write_y尚未运行,这意味着if条件失败,z不会增加,在这种情况下,只有x为true,y仍为false。一旦write_y运行,read_y_then_x就会跳出其循环,但是x和y都为true,z会增加,而断言不会触发。我想不到任何“运行”或内存排序,其中z从未增加。有人能解释一下我的推理有什么问题吗?另外,我知道循环读取将始终在if语句读取之前,因为acquire会防止此重新排序。
memory_order_seq_cst以避免断言。 - Wycky” 不意味着此写入在当前线程中可见。 - xskxzr