我正在尝试压缩长向量(其大小从1到1亿个元素不等)。向量中的正整数值范围为0到1亿(取决于向量大小),因此我使用32位整数来包含大数,但这会消耗过多的存储空间。向量具有以下特征:
以下是向量的一部分的绘图: 我想要什么?
因为我使用32位整数,这浪费了很多内存,因为可以用少于32位表示的较小数字也会重复出现。我希望最大限度地压缩此向量以节省内存(理想情况下,压缩因子应达到3,因为只有降低这个量或更多才能满足我们的需求!)。哪种最佳压缩算法可实现此目的?或者是否有方法利用上述数组的特征将该数组中的数字可逆转换为8位整数?
我想要什么?
因为我使用32位整数,这浪费了很多内存,因为可以用少于32位表示的较小数字也会重复出现。我希望最大限度地压缩此向量以节省内存(理想情况下,压缩因子应达到3,因为只有降低这个量或更多才能满足我们的需求!)。哪种最佳压缩算法可实现此目的?或者是否有方法利用上述数组的特征将该数组中的数字可逆转换为8位整数?
我尝试过或考虑过的事情:
- 所有值都是正整数。随着向量大小的增加,它们的范围也会增加。
- 值递增,但较小的数字经常出现(请参见下图)。
- 特定索引之前的所有值都不大于该索引(索引从零开始)。例如,在索引6之前发生的任何值都不大于6。但是,在该索引之后,较小的值可能会重复。对于整个数组,这仍然成立。
- 通常处理非常长的数组。因此,随着数组长度超过100万个元素,即将出现的数字大多是与先前重复出现的数字混合的大数字。较短的数字通常比较大的数字更容易重复出现。通过遍历数组,可以将新的较大数字添加到数组中。
以下是向量的一部分的绘图:
我想要什么?
因为我使用32位整数,这浪费了很多内存,因为可以用少于32位表示的较小数字也会重复出现。我希望最大限度地压缩此向量以节省内存(理想情况下,压缩因子应达到3,因为只有降低这个量或更多才能满足我们的需求!)。哪种最佳压缩算法可实现此目的?或者是否有方法利用上述数组的特征将该数组中的数字可逆转换为8位整数?我尝试过或考虑过的事情:
- Delta编码:由于向量不总是单调递增,因此此方法在此处无法使用。
- Huffman编码:由于数组中唯一数字的范围相当大,因此似乎在这里不起作用,因为编码表将是一个很大的开销。
- 使用可变Int编码。即对较小的数字使用8位整数,对较大的数字使用16位...等。这已经将向量大小减小到size*0.7(不令人满意,因为它没有利用上述特定特性)。
- 我不确定下面链接中描述的方法是否适用于我的数据:http://ygdes.com/ddj-3r/ddj-3r_compact.html 我不太理解这种方法,但它鼓励我尝试类似的事情,因为我认为数据中有一些可以利用的顺序。 例如,我尝试重新分配任何大于255的数字(n)到n-255,以便我可以保持整数在8位领域内,因为我知道在该索引之前没有数字大于255。然而,我无法区分重新分配的数字和重复的数字...所以除非进行一些更多的技巧来反转重新分配,否则这个想法行不通...
这是前24000个元素的数据链接,供感兴趣的人使用: data
非常感谢任何建议或建议。提前致谢。
编辑1:
这是Delta编码后数据的图。如您所见,它并没有减少范围!
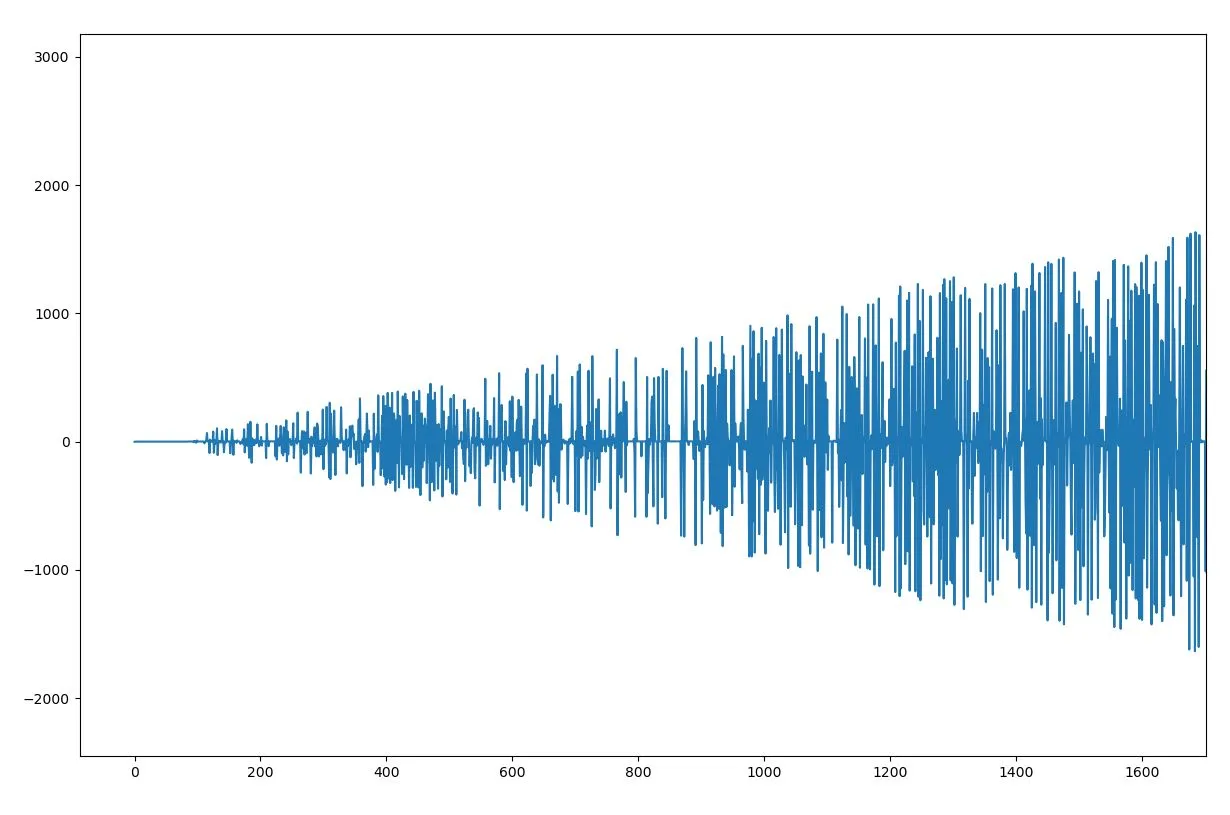
编辑2:
我希望能在数据中找到一种模式,使我可以将32位向量可逆地转换为单个8位向量,但这似乎非常不可能。 我尝试将32位向量分解为4个8位向量,希望分解向量更容易压缩。 下面是4个向量的图。现在它们的范围是0-255。 我所做的是将向量中的每个元素递归地除以255,并将余数存储到另一个向量中。要重构原始数组,我需要做的就是:(((vec4*255)+vec3)*255+vec2)*255+vec1...

https://drive.google.com/file/d/10wO3-1j3NkQbaKTcr0nl55bOH9P-G1Uu/view?usp=sharing
编辑3:
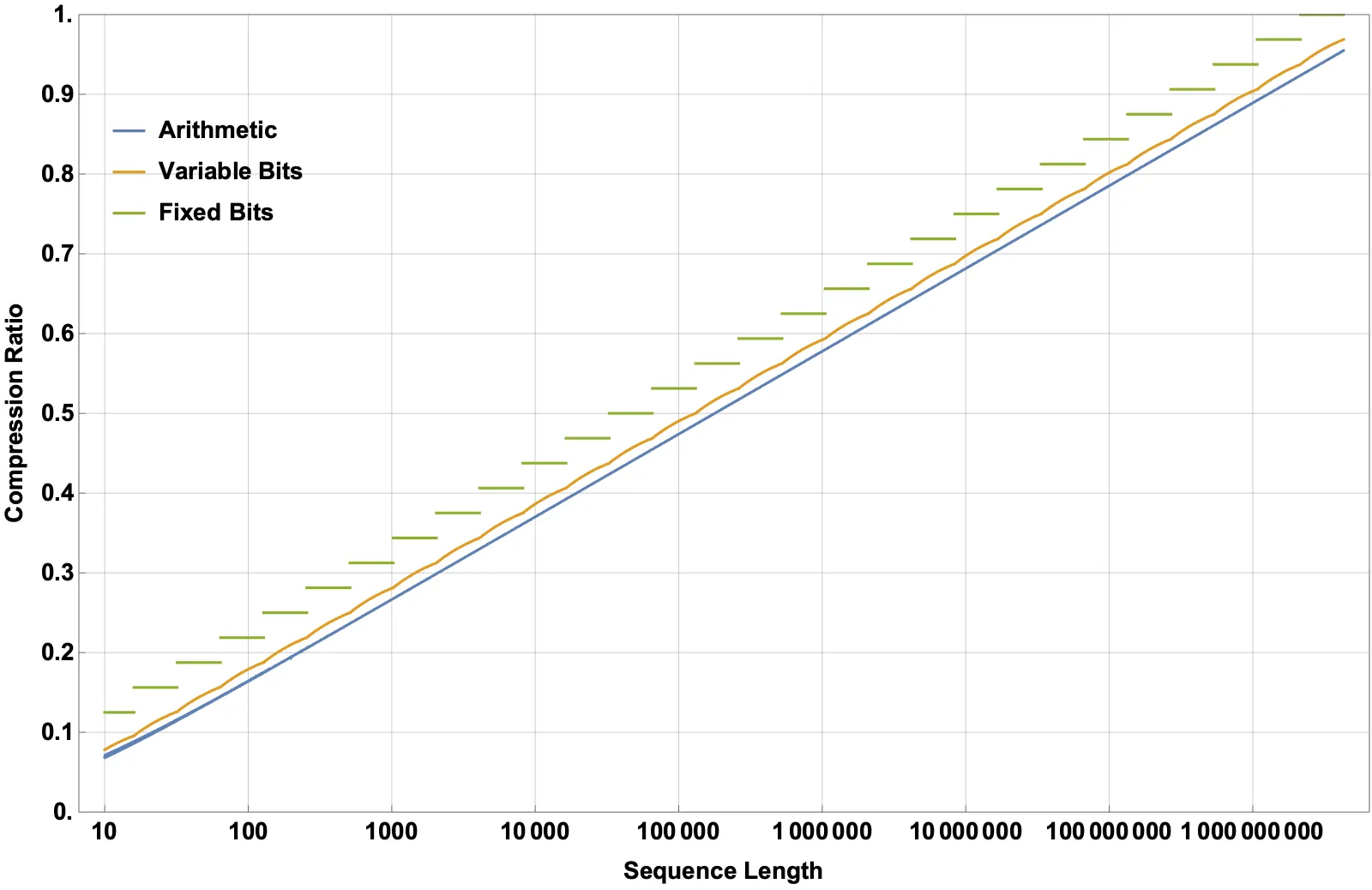
非常感谢所有提供答案的人。我从中学到了很多。如果您有兴趣玩弄更大的数据集,以下链接有1100万个类似数据集的元素(压缩后33MB)。
https://drive.google.com/file/d/1Aohfu6II6OdN-CqnDll7DeHPgEDLMPjP/view
一旦解压数据,您可以使用以下C++代码片段将数据读入vector<int32_t>中。 const char* path = "path_to\compression_int32.txt";
std::vector<int32_t> newVector{};
std::ifstream ifs(path, std::ios::in | std::ifstream::binary);
std::istream_iterator<int32_t> iter{ ifs };
std::istream_iterator<int32_t> end{};
std::copy(iter, end, std::back_inserter(newVector));
0, 1, 2, 3, 4, 5, 6, 4, 7, 4, 8, 9, 1, 10, 11, 12, 13, 14, 15, 16, 16, 17, 18, 19, 19, 6, 6, 6, 20, 160开头。在索引30处出现的160与特征三不太匹配。 - user58697