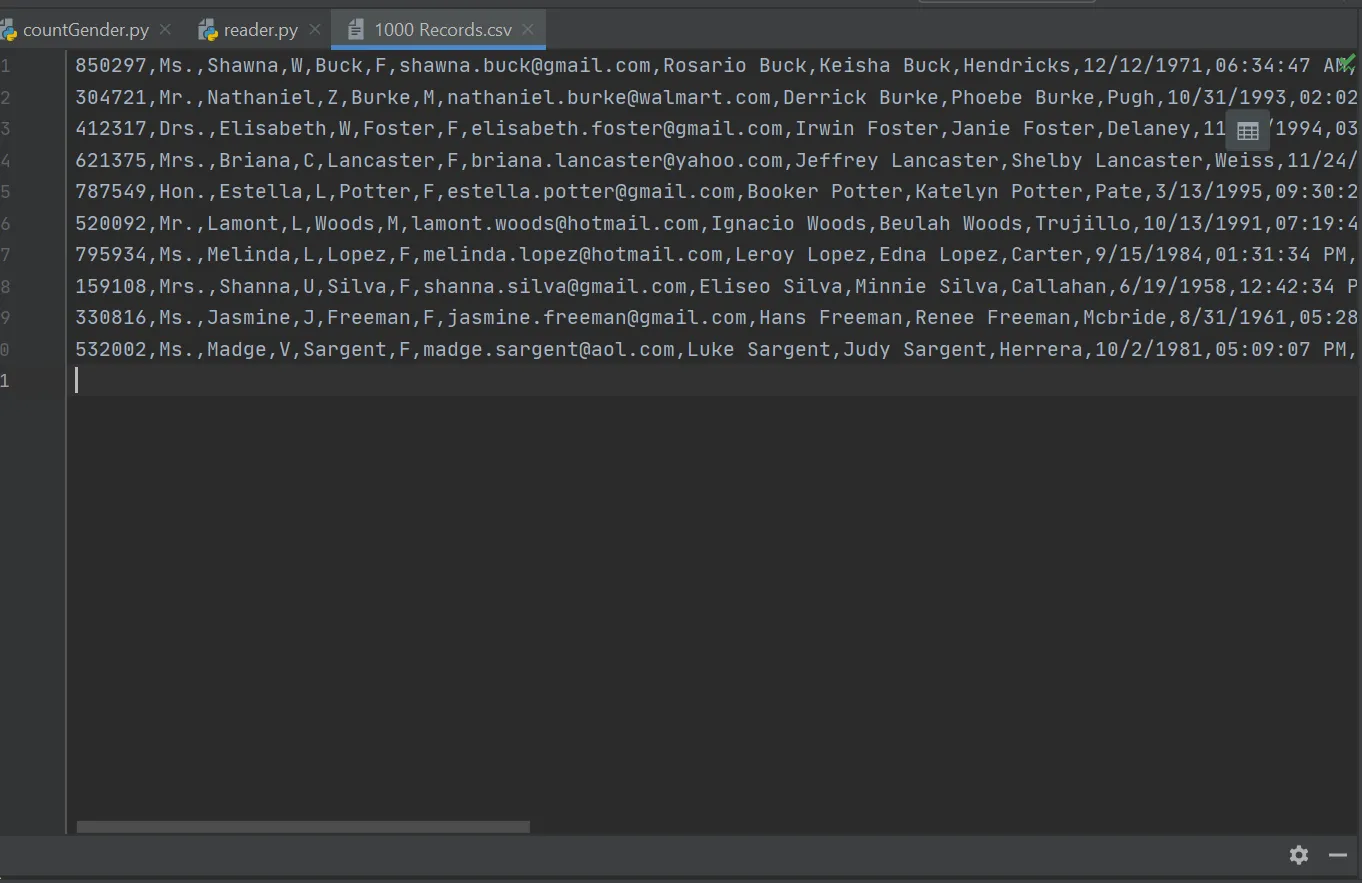
我希望能够分别计算男性和女性的电子邮件账户,但我编写的代码无法正常工作,有人可以帮忙吗?以下是我的代码,提前感谢您的帮助。
import csv
mailAcc = {}
femailAcc = {}
with open('1000 Records.csv', 'r') as csv_file:
csv_reader = csv.reader(csv_file)
for i in csv_reader:
email = i[6]
gender = i[5]
doman = email.split('@')[-1]
if doman in mailAcc:
if gender == 'm':
mailAcc[doman] = mailAcc[doman] + 1
else:
mailAcc[doman] = 1
if doman in femailAcc:
if gender == 'F':
femailAcc[doman] = femailAcc[doman] + 1
else:
femailAcc[doman] = 1
print('Mail Email accounts: ', mailAcc)
print('Femail Email Accounts: ', femailAcc)