简而言之,我在使用Postgresql、Node.js和node-postgres的数据API时,遇到了一个问题,即每分钟支持超过5000个读请求的困难。瓶颈似乎出现在API和数据库之间。以下是实现细节。
我正在使用AWS的Postgresql RDS数据库实例(m4.4xlarge-64 GB内存,16个虚拟CPU,350 GB SSD,没有预留的IOPS)作为Node.js驱动的数据API。默认情况下,RDS的max_connections=5000。Node API在两个集群中进行负载均衡,每个集群有4个进程(2个具有4个虚拟CPU的Ec2实例,在集群模式下使用PM2运行API)。我使用node-postgres将API绑定到Postgresql RDS,并尝试使用其连接池功能。以下是我的连接池代码示例:
使用这个实现并通过负载测试器进行测试,我可以在一分钟内支持大约5000个请求,平均响应时间约为190毫秒(这是我预期的)。一旦我每分钟发出超过5000个请求,我的响应时间就会增加到1200毫秒以上,最糟糕的情况下API开始频繁超时。监控显示,运行Node.js API的EC2的CPU利用率保持在10%以下。因此,我的重点是数据库和API与数据库的绑定。
我尝试增加(或减少)node-postgres的“max”连接设置,但API的响应/超时行为没有改变。我还尝试了在RDS上使用预配置的IOPS,但没有改善。有趣的是,我将RDS扩展到m4.10xlarge(160 GB内存,40个虚拟CPU),虽然RDS的CPU利用率大大降低,但API的整体性能却明显恶化(甚至无法支持我之前能够使用较小的RDS支持的每分钟5000个请求)。
我在很多方面都处于陌生的领域,对于如何确定在每分钟超过5000个请求时,哪个部分是限制API性能的瓶颈感到不确定。如前所述,我已经根据Postgresql配置文档和node-postgres文档的审查尝试了各种调整,但都没有成功。
如果有人对如何诊断或优化有建议,我将非常感激。
更新:
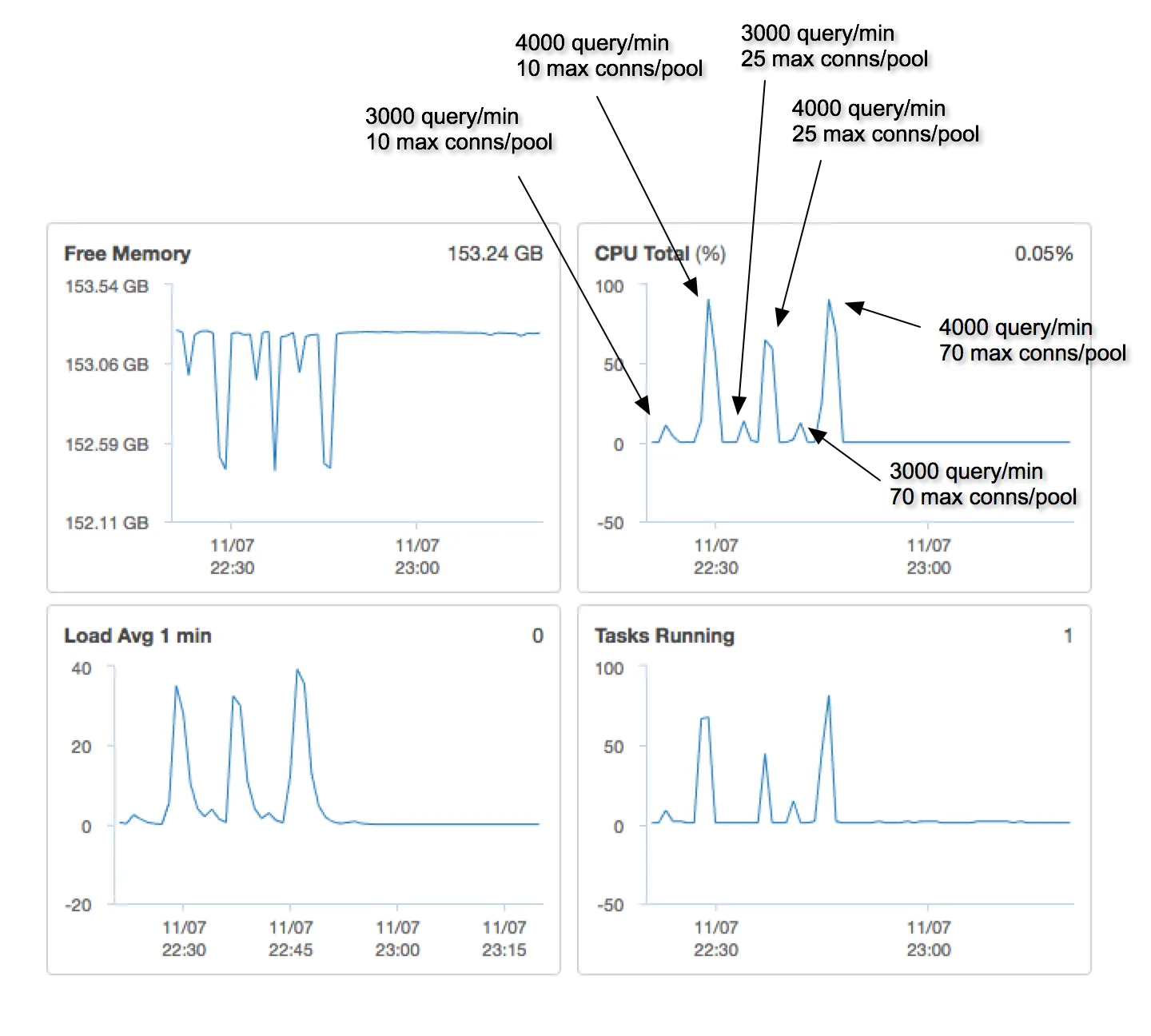
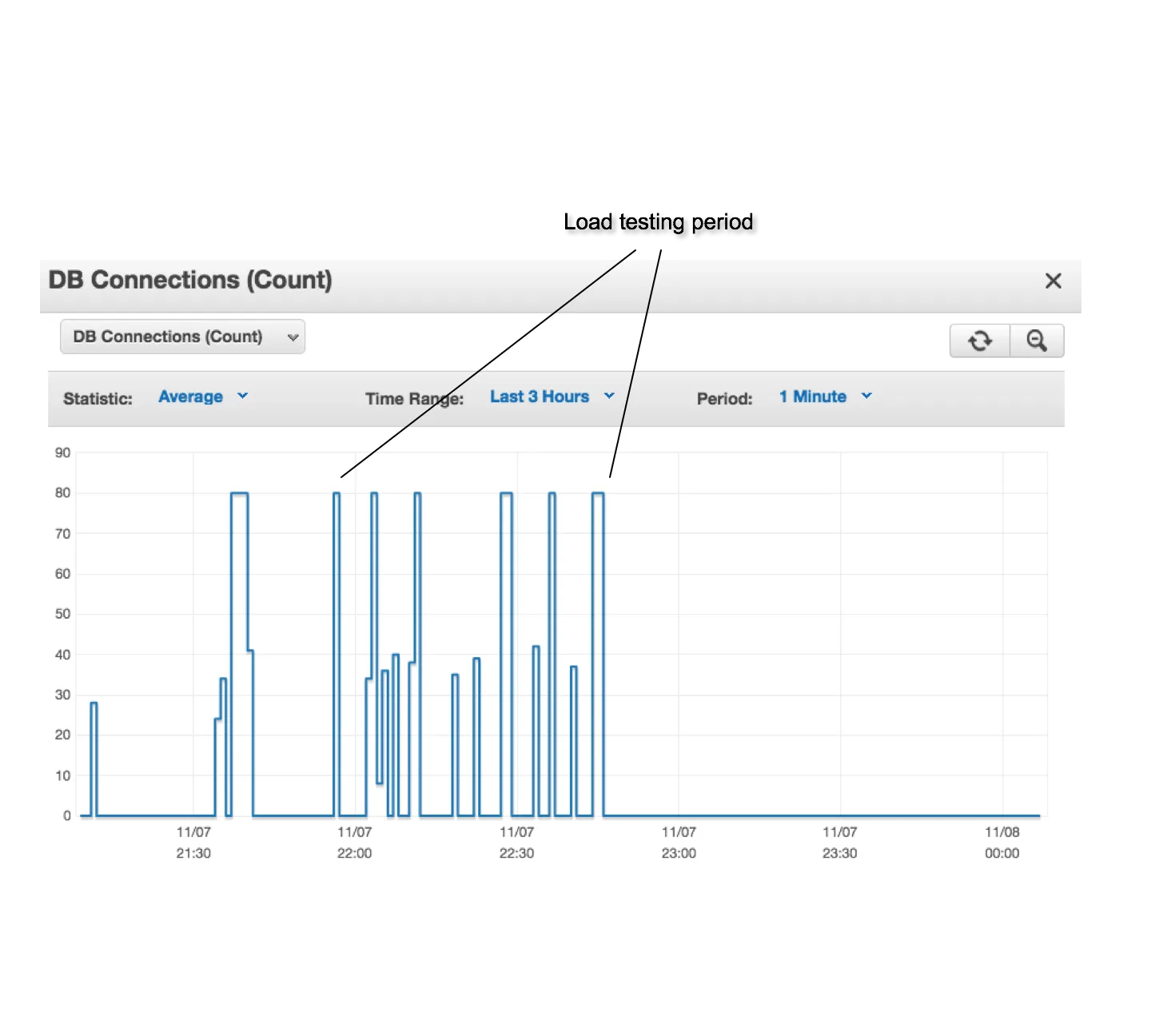
在升级到m4.10xlarge后,我进行了一系列的负载测试,变化了每分钟请求的数量和每个连接池的最大连接数。这里是一些监控指标的屏幕截图。
我正在使用AWS的Postgresql RDS数据库实例(m4.4xlarge-64 GB内存,16个虚拟CPU,350 GB SSD,没有预留的IOPS)作为Node.js驱动的数据API。默认情况下,RDS的max_connections=5000。Node API在两个集群中进行负载均衡,每个集群有4个进程(2个具有4个虚拟CPU的Ec2实例,在集群模式下使用PM2运行API)。我使用node-postgres将API绑定到Postgresql RDS,并尝试使用其连接池功能。以下是我的连接池代码示例:
var pool = new Pool({
user: settings.database.username,
password: settings.database.password,
host: settings.database.readServer,
database: settings.database.database,
max: 25,
idleTimeoutMillis: 1000
});
/* Example of pool usage */
pool.query('SELECT my_column FROM my_table', function(err, result){
/* Callback code here */
});
使用这个实现并通过负载测试器进行测试,我可以在一分钟内支持大约5000个请求,平均响应时间约为190毫秒(这是我预期的)。一旦我每分钟发出超过5000个请求,我的响应时间就会增加到1200毫秒以上,最糟糕的情况下API开始频繁超时。监控显示,运行Node.js API的EC2的CPU利用率保持在10%以下。因此,我的重点是数据库和API与数据库的绑定。
我尝试增加(或减少)node-postgres的“max”连接设置,但API的响应/超时行为没有改变。我还尝试了在RDS上使用预配置的IOPS,但没有改善。有趣的是,我将RDS扩展到m4.10xlarge(160 GB内存,40个虚拟CPU),虽然RDS的CPU利用率大大降低,但API的整体性能却明显恶化(甚至无法支持我之前能够使用较小的RDS支持的每分钟5000个请求)。
我在很多方面都处于陌生的领域,对于如何确定在每分钟超过5000个请求时,哪个部分是限制API性能的瓶颈感到不确定。如前所述,我已经根据Postgresql配置文档和node-postgres文档的审查尝试了各种调整,但都没有成功。
如果有人对如何诊断或优化有建议,我将非常感激。
更新:
在升级到m4.10xlarge后,我进行了一系列的负载测试,变化了每分钟请求的数量和每个连接池的最大连接数。这里是一些监控指标的屏幕截图。