只因1兆字节和100万字节之间的差异,才有此解决方案。有约2的8093729.5次方种选择1百万个8位数字(允许重复且顺序不重要)的不同方式,因此只拥有1百万字节RAM的机器无法表示所有可能性。但1M(减去TCP/IP的2k)等于1022*1024*8 = 8372224位,因此可以找到解决方案。
第一部分,初始解决方案
这种方法需要略多于1M,我将对其进行优化以适应1M的限制。
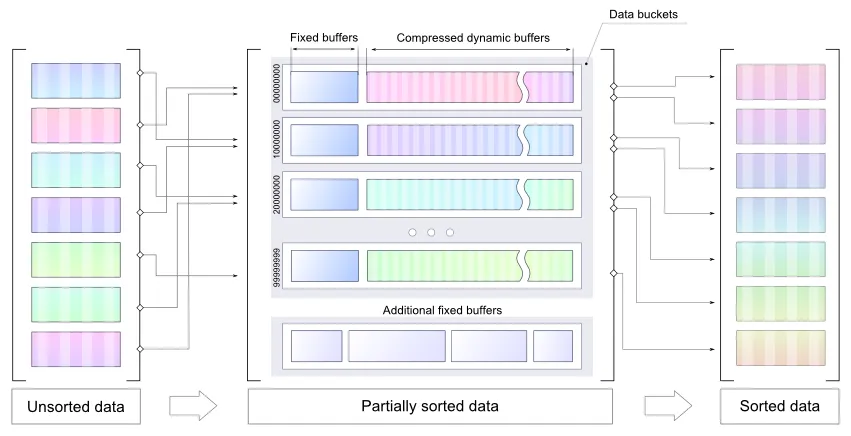
我将按照子列表的顺序存储0到99999999范围内的数字的紧凑排序列表,作为7位数字的子列表序列。第一个子列表包含从0到127的数字,第二个子列表包含从128到255的数字,以此类推。100000000/128正好是781250,因此需要781250个这样的子列表。
每个子列表由一个2位的子列表头和一个子列表主体组成。子列表主体占用每个子列表条目的7位。所有子列表都连接在一起,并且格式使得可以确定一个子列表的结束位置和下一个子列表的开始位置。完全填充的列表所需的总存储空间为2*781250 + 7*1000000 = 8562500位,约为1.021兆字节。
4个可能的子列表头值如下:
00 空的子列表,没有后续内容。
01 单元素列表,子列表中只有一个条目,下一个7位存储该条目。
10 子列表至少包含2个不同的数字。这些条目以非递减的顺序存储,但最后一个条目小于或等于第一个条目。这样可以识别子列表的结尾。例如,数字2、4、6将存储为(4,6,2)。数字2、2、3、4、4将存储为(2,3,4,4,2)。
11 子列表包含两个或更多个单个数字的重复。下一个7位给出了该数字。然后是零个或多个带有值1的7位条目,后跟一个具有值0的7位条目。子列表主体的长度规定了重复次数。例如,数字12、12将存储为(12,0),数字12、12、12将存储为(12,1,0),数字12、12、12、12将存储为(12,1,1,0)等等。
我从空列表开始,读入一堆数字并将它们存储为32位整数,原地排序新数字(可能使用堆排序),然后将它们合并到一个新的紧凑排序列表中。重复此操作,直到没有更多的数字可读取,然后再次遍历紧凑列表以生成输出。
下面的行表示在列表合并操作开始之前的内存状态。 "O"是保存已排序的32位整数的区域。 "X"是保存旧紧凑列表的区域。 "="表示用于紧凑列表的扩展空间,每个“O”中有7位整数。 "Z"是其他随机开销。
ZZZOOOOOOOOOOOOOOOOOOOOOOOOOO==========XXXXXXXXXXXXXXXXXXXXXXXXXX
合并例程从最左边的“O”和最左边的“X”开始读取,并从最左边的“=”开始写入。直到合并所有新整数,写指针才会捕捉到紧凑列表读取指针,因为两个指针对于每个子列表前进2位并且对于旧紧凑列表中的每个条目前进7位,并且有足够的额外空间用于新数字的7位条目。
第二部分,把它压缩成1M
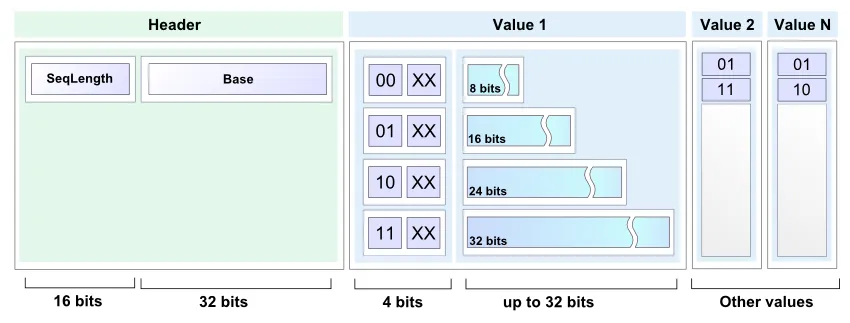
为了将上述解决方案压缩到1M,我需要使紧凑列表格式更加紧凑。我会摆脱其中一种子列表类型,这样就只有3种不同的可能的子列表头值了。然后我可以使用“00”,“01”和“1”作为子列表头值并节省一些位。子列表类型是:
A 空的子列表,没有任何内容跟随。
B 单例,子列表中只有一个条目,下一个7位保存它。
C 子列表至少包含2个不同的数字。 条目按非递减顺序存储,除了最后一个条目小于或等于第一个条目。这允许确定子列表的末尾。例如,数字2,4,6将存储为(4,6,2)。数字2,2,3,4,4将存储为(2,3,4,4,2)。
D 子列表由单个数字的2个或更多重复组成。
我的3个子列表头值将是“A”,“B”和“C”,所以我需要一种方法来表示D类型子列表。
假设我有C类型子列表标题,后跟3个条目,例如“C [17] [101] [58]”。根据上述描述,这不能是有效的C类型子列表的一部分,因为第三个条目小于第二个但大于第一个。我可以使用这种类型的构造来表示D类型子列表。在位方面,无论何处我都有“C {00????}{1????}{01????”}都是不可能的C类型子列表。我将使用此来表示由单个数字的3个或更多重复组成的子列表。前两个7位字编码数字(下面的“N”位),后跟零个或多个{0100001}字,后跟{0100000}字。
For example, 3 repetitions: "C{00NNNNN}{1NN0000}{0100000}", 4 repetitions: "C{00NNNNN}{1NN0000}{0100001}{0100000}", and so on.
这里只剩下只包含单个数字2次重复的列表。我将使用另一个不可能的C类型子列表模式表示它们:"C{0??????}{11?????}{10?????}"。前两个字中有足够空间存储7位数字,但是该模式比所表示的子列表更长,这使得事情变得有些复杂。末尾的五个问号可以被认为不是模式的一部分,因此我的模式为:"C{0NNNNNN}{11N????}10",其中要重复的数字存储在“N”中。这多出了2位。
我需要借用2位,并从该模式中未使用的4位中归还它们。在读取时,当遇到“C{0NNNNNN}{11N00AB}10”时,输出“N”中的2个实例,用A和B位覆盖末尾的“10”,并将读指针向后退回2位。对于这个算法来说,破坏性读取是可以的,因为每个紧凑列表只被处理一次。
在写入单个数字2次重复的子列表时,写入“C{0NNNNNN}11N00”,并将借用的位计数器设置为2。在借用位计数器非零的每次写入时,每写入1位就会减少1,当计数器达到零时,写入“10”。因此,接下来写入的2位将进入A和B位,然后“10”将被放置在末尾。
对于3个子列表头值,我使用“00”、“01”和“1”,并将“1”分配给最常见的子列表类型。我需要一个小表将子列表头值映射到子列表类型,并且我需要每个子列表类型的出现计数器,以便我知道最佳的子列表头映射是什么。
当所有子列表类型等受欢迎时,完全填充的紧凑列表的最坏情况下的最小表示法是发生。在这种情况下,对于每3个子列表头,我可以节省1位,因此列表大小为2*781250 + 7*1000000 - 781250/3 = 8302083.3位。向32位字边界舍入,即8302112位,或1037764字节。
从1M中减去TCP/IP状态和缓冲区的2k是1022 * 1024 = 1046528字节,留给我的可用空间是8764字节。
但是更改子列表头映射的过程怎么办?在下面的内存映射中,“Z”是随机开销,“=”是空闲空间,“X”是紧凑列表。
ZZZ=====XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
从最左边的 "X" 开始阅读,从最左边的 "=" 开始写作,并向右工作。完成后,紧凑列表将会稍微缩短,并位于内存的错误端:
ZZZXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX=======
那么我需要把它移到右边:
ZZZ=======XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
在头映射更改过程中,多达1/3的子列表头将从1位变为2位。在最坏的情况下,这些所有更改都将在列表的开头,因此我至少需要 781250/3 位的可用存储空间才能开始,这使我回到了先前版本的压缩列表的内存需求:(为了解决这个问题,我将781250个子列表分成10个子列表组,每个组有自己独立的子列表头映射。使用字母A到J来表示这些组:
ZZZ=====AAAAAABBCCCCDDDDDEEEFFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
每个子列表组在子列表头映射更改期间会收缩或保持不变:
ZZZ=====AAAAAABBCCCCDDDDDEEEFFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAA=====BBCCCCDDDDDEEEFFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABB=====CCCCDDDDDEEEFFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCC======DDDDDEEEFFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDD======EEEFFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDDEEE======FFFGGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDDEEEFFF======GGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDDEEEFFFGGGGGGGGGG=======HHIJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDDEEEFFFGGGGGGGGGGHH=======IJJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDDEEEFFFGGGGGGGGGGHHI=======JJJJJJJJJJJJJJJJJJJJ
ZZZAAAAAABBCCCDDDDDEEEFFFGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ=======
ZZZ=======AAAAAABBCCCDDDDDEEEFFFGGGGGGGGGGHHIJJJJJJJJJJJJJJJJJJJJ
在映射更改期间,子列表组的最坏情况临时扩展是78125/3 = 26042位,在4k以下。如果我允许使用4k加上1037764字节来完全填充紧凑列表,那么剩下的空间是8764-4096 = 4668字节来存储内存映射中的“Z”。
对于10个子列表头映射表、30个子列表头出现计数和其他少量计数器、指针和小缓冲区,应该足够了。还有一些被用作函数调用返回地址和本地变量堆栈空间等我没有注意到的空间。
第三部分,需要多长时间才能运行?
使用空紧凑列表时,1位列表头将用于一个空子列表,并且列表的起始大小将为781250位。在最坏的情况下,列表每增加一个数字就会增长8位,因此每个32位数字需要40位的自由空间放置在列表缓冲区顶部,然后进行排序和合并。在最坏的情况下,更改子列表头映射会导致2 * 781250 + 7 * entries - 781250 / 3位的空间使用率。
采用在列表中有至少800000个数字之后每五次合并更改子列表头映射的策略,最坏情况下运行将涉及大约30M的紧凑列表读写活动。
来源:
http://nick.cleaton.net/ramsortsol.html