虽然可能稍晚了一些,但我最近遇到了这个错误,而且在搜索此问题时,没有任何结果能让我理解除了连接泄漏 - 而这并不是我的问题。
如果这可以帮助其他人,我将解释问题、解决方案以及我发现的一些有用信息,因为我在其他地方找不到它们。
在我的情况下,根本原因是由于未对键列进行模型属性注释,而这些键列是字符串。例如:
public class InventoryItem
{
public string StateCode {get;set;}
public string CompanyId {get;set;}
public int Id {get;set;}
}
在我的DbContext中,我配置了关键列为复合主键。
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<InventoryItem>().HasKey(x => new { x.StateCode, x.CompanyId, x.Id });
}
SQL表定义
CREATE TABLE [Example].[InventoryItem] (
[Id] INT NOT NULL,
[StateCode] VARCHAR (2) NOT NULL,
[CompanyId] VARCHAR (50) NOT NULL,
CONSTRAINT [PK_InventoryItems] PRIMARY KEY CLUSTERED ([StateCode] ASC, [CompanyId] ASC, [Id] ASC)
)
C#查询代码
public List<InventoryItem> GetAllCompanyInventory(string stateCode, string companyId)
{
using (var context = ContextFactory.CreateContext())
{
return await context.InventoryItems.Where(x => x.StateCode == stateCode && x.CompanyId == companyId).ToListAsync().ConfigureAwait(false);
}
}
在这种情况下,发生的事情是stateCode和companyId被参数化为,而查询正在使用CONVERT_IMPLICIT,这实际上导致系统无法正确使用索引。我的CPU和工作时间都达到了100%,不知何故,这转化为了连接池问题。在对这些属性添加注释之后,我的CPU从未超过5%,也再没有看到过连接池问题。以下是帮助我识别此问题的一些方法。
修复方法是对这些属性进行注释。
public class InventoryItem
{
[System.ComponentModel.DataAnnotations.Schema.Column(TypeName = "varchar(2)")]
public string StateCode {get;set;}
[System.ComponentModel.DataAnnotations.Schema.Column(TypeName = "varchar(50)")]
public string CompanyId {get;set;}
public int Id {get;set;}
}
改动后,服务器几乎处于睡眠状态。运行sp_who显示连接数更少,几乎全部都在休眠。
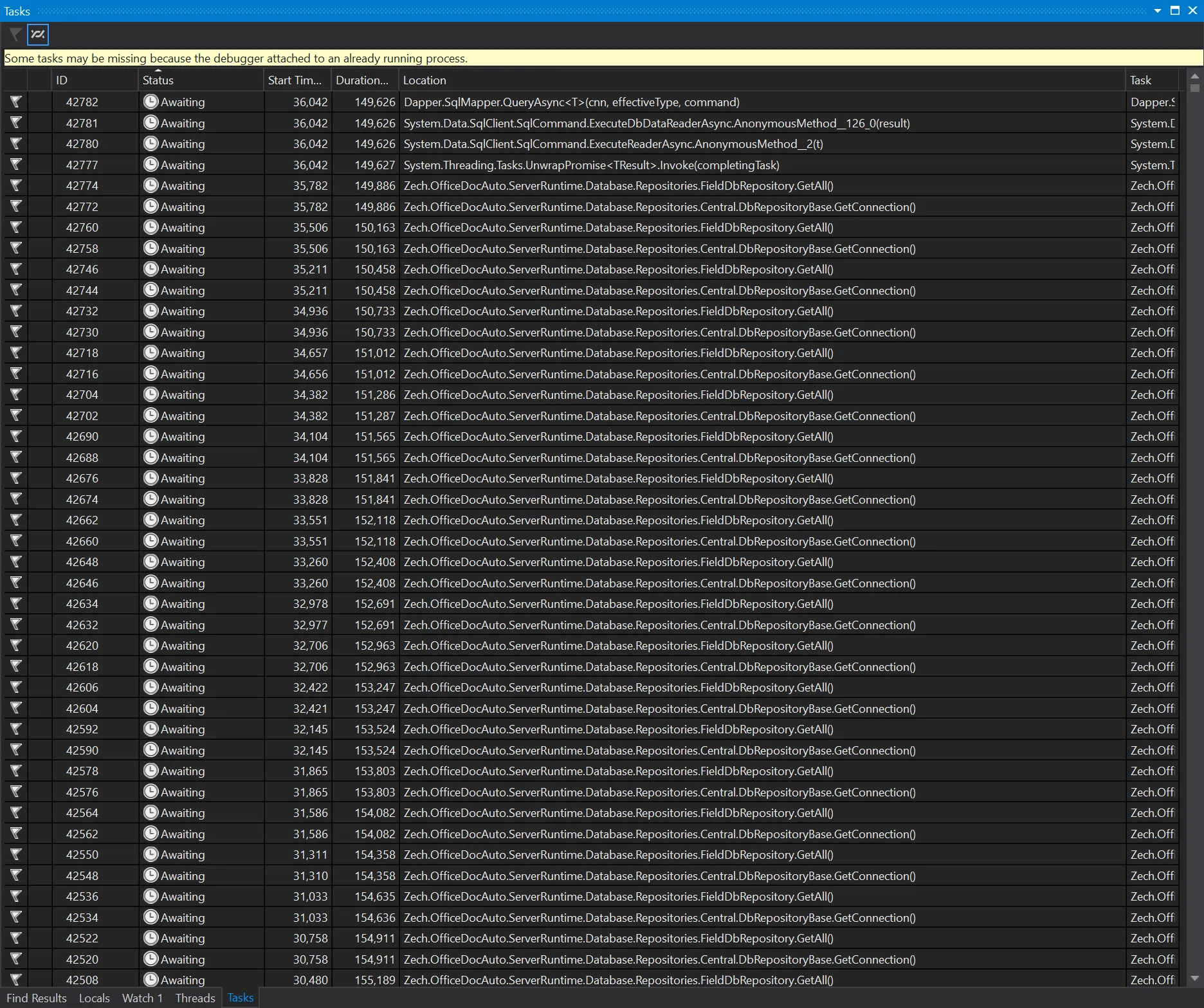
在此期间,有人提到使用sp_who查看活动连接。我可以看到当我开始在本地运行我的代码时,连接数从0增加到最大允许值,所有连接列表都包含我的主机名和运行状态。因此我认为我的代码有错误,但实际上我们每次创建上下文的地方都被适当地包装了using语句。我感觉快要失去理智了。然后我转变思路,认为这可能是症状而不是实际问题。这导致我找到了解决问题的途径。
我找到这篇文章,最终引出了这个SQL语句,它真正帮助我识别了发生了什么。
SELECT TOP 20
(total_logical_reads/execution_count) AS avg_logical_reads,
(total_logical_writes/execution_count) AS avg_logical_writes,
(total_physical_reads/execution_count) AS avg_phys_reads,
(total_worker_time/execution_count) AS avg_cpu_over_head,
total_logical_reads, total_logical_writes, total_physical_reads,
total_worker_time, execution_count, total_elapsed_time AS Duration,
plan_generation_num AS num_recompiles,
statement_start_offset AS stmt_start_offset,
(SELECT SUBSTRING(text, statement_start_offset/2 + 1,
(CASE WHEN statement_end_offset = -1
THEN LEN(CONVERT(nvarchar(MAX),text)) * 2
ELSE statement_end_offset
END - statement_start_offset)/2)
FROM sys.dm_exec_sql_text(sql_handle)) AS query_text,
(SELECT query_plan FROM sys.dm_exec_query_plan(plan_handle)) AS query_plan
FROM sys.dm_exec_query_stats a
ORDER BY (total_logical_reads + total_logical_writes)/execution_count DESC
从这里,我可以获取查询文本和查询计划,发现一些输出的总工作时间超过40亿,而其他重要的查询只有大约3亿。这些超高的工作时间并不是预期的,因为它们在搜索谓词中确切地使用了索引键。查看实际查询计划,我能看到一些东西:
- 需要读取极高的行数(例如,估计每次执行行数仅为1,但需要读取的行数超过1000万)
- 使用了
CONVERT_IMPLICIT
- 建议创建另一个索引,但实际上已经有了一个相同的索引(简化示例有点复杂,但实际索引有更多列,省略前两列以避免转换)
这篇文章帮助我理解了即使有一个使用我正在搜索的确切键的索引,为什么我的估计行数还是那么高。
这篇文章帮助我理解了我正在审查的查询计划中的CONVERT_IMPLICIT调用。
我找到了上面的文章,因为它在
这篇帖子中提到。
这篇文章帮助我找出如何将默认值从nvarchar更改为varchar。
我仍然不确定为什么这会导致连接池超时问题。我有一些测试正在运行,每次只执行一个状态代码+公司ID,但几乎立即就会出现此错误。一旦我添加了注释,即使同时处理多个请求,一切都变得清晰明了。