我正在学习Spark,对执行器内存的分割有些疑问。具体来说,在Spark Apache文档(这里)中指出:
这是其中一个例子:Java堆空间分为两个区域:年轻代和老年代。年轻代用于保存短生命周期的对象,而老年代则用于保存长生命周期的对象。
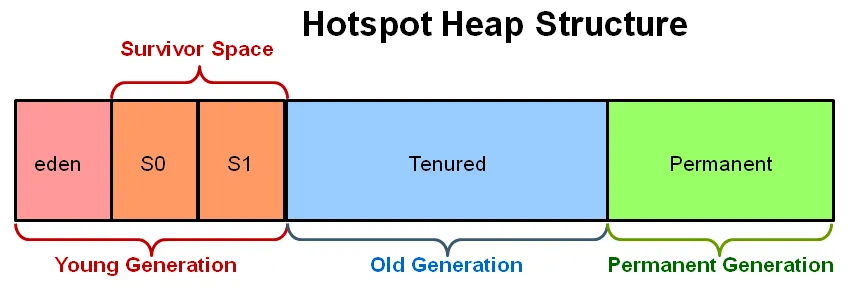
但是对于Spark Executor而言,内存还有另一个抽象的分割,正如Spark Apache文档(此处)所述:
Spark中的内存使用主要可以分为两类:执行和存储。执行内存指用于洗牌、连接、排序和聚合等计算的内存,而存储内存指用于缓存和在集群中传播内部数据的内存。在Spark中,执行和存储共享一个统一的区域(M)。
如下图所示:
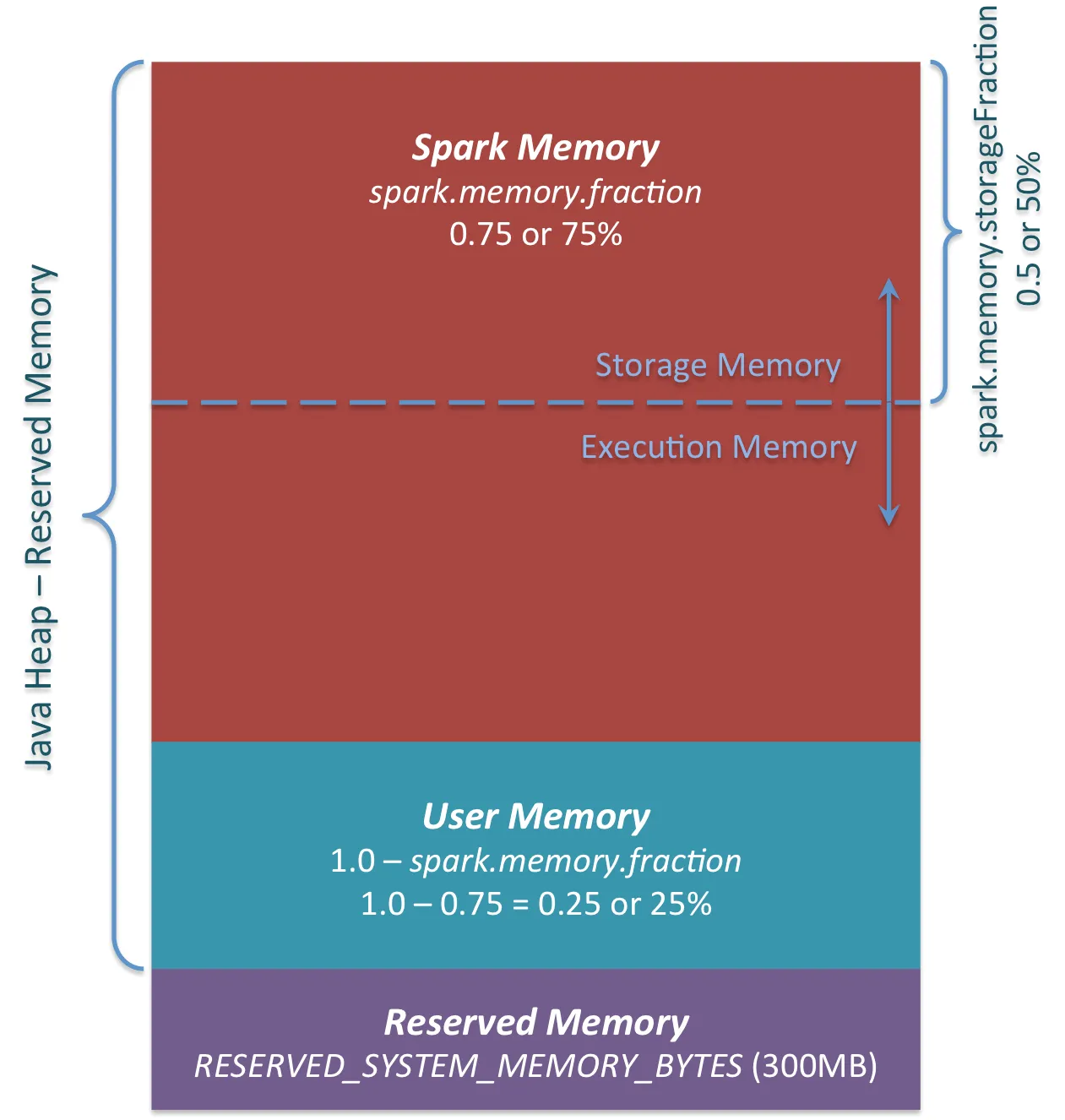
spark.memory.fraction将M的大小表示为(JVM堆空间-300MiB)(默认值0.6)的一部分。其余空间(40%)保留给用户数据结构、Spark内部元数据以及在出现稀疏和异常大记录的情况下防止OOM错误。
其中spark.memory.fraction代表Java Heap的执行\存储内存部分。
但是
如果OldGen接近饱和状态,请通过降低spark.memory.fraction来减少缓存使用的内存量;缓存较少的对象比减慢任务执行更好。
这似乎表明OldGen实际上是用户内存,但以下语句似乎与我的假设相矛盾
如果OldGen接近饱和状态,则可以考虑减小Young generation的大小。
我看漏了什么?
Young Gen和Old Gen的划分与Spark分数和用户内存有什么关系?