我找到了一种确定字体是否支持Unicode-16字符的方法。不幸的是,这对于代理对Unicode字符并不适用,因为由
以下是我尝试做的示例:
如果我在Windows 10上运行它,我会得到这个:
然后:
GetFontUnicodeRanges函数支持的WCRANGE结构只返回WCHAR(16位)参数作为输出。以下是我尝试做的示例:
LRESULT CALLBACK WndProc(HWND hWnd, UINT message, WPARAM wParam, LPARAM lParam)
{
static HFONT hFont = NULL;
switch (message)
{
case WM_CREATE:
{
LOGFONT lf = {0};
lf.lfHeight = -64;
::StringCchCopy(lf.lfFaceName, _countof(lf.lfFaceName), L"Arial");
hFont = ::CreateFontIndirect(&lf);
}
break;
case WM_PAINT:
{
PAINTSTRUCT ps;
HDC hdc = BeginPaint(hWnd, &ps);
RECT rcClient = {0};
::GetClientRect(hWnd, &rcClient);
HGDIOBJ hOldFont = ::SelectObject(hdc, hFont);
LPCTSTR pStr = L">\U0001F609<";
int nLn = wcslen(pStr);
RECT rc = {20, 20, rcClient.right, rcClient.bottom};
::DrawText(hdc, pStr, nLn, &rc, DT_NOPREFIX | DT_SINGLELINE);
::SelectObject(hdc, hOldFont);
EndPaint(hWnd, &ps);
}
break;
//....
如果我在Windows 10上运行它,我会得到这个:
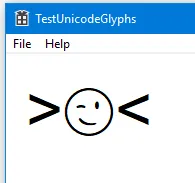
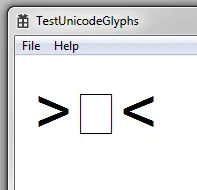
那么如何判断中间字符是否不会被呈现?
PS. 我也尝试使用文档不够清晰的 Uniscribe 和修改过的 this tutorial 作为示例。但无论我做了什么,都无法在Win10和Win7之间产生可辨别的结果。如果这有助于回答这个问题,这是我尝试的代码:
//Call from WM_PAINT handler
std::wstring str;
test02(hdc, pStr, str);
RECT rc0 = {0, 200, rcClient.right, rcClient.bottom};
::DrawText(hdc, str.c_str(), str.size(), &rc0, DT_NOPREFIX | DT_SINGLELINE);
然后:
void test02(HDC hDc, LPCTSTR pStr, std::wstring& str)
{
//'str' = receives debugging outcome (needs to be printed on the screen)
//SOURCE:
// https://maxradi.us/documents/uniscribe/
HRESULT hr;
SCRIPT_STRING_ANALYSIS ssa = {0};
int nLn = wcslen(pStr);
hr = ::ScriptStringAnalyse(hDc,
pStr,
nLn,
1024,
-1,
SSA_GLYPHS,
0, NULL, NULL, NULL, NULL, NULL, &ssa);
if(SUCCEEDED(hr))
{
const SCRIPT_PROPERTIES **g_ppScriptProperties;
int g_iMaxScript;
hr = ::ScriptGetProperties(&g_ppScriptProperties, &g_iMaxScript);
if(SUCCEEDED(hr))
{
const int cMaxItems = 20;
SCRIPT_ITEM si[cMaxItems + 1];
SCRIPT_ITEM *pItems = si;
int cItems; //Receives number of glyphs
SCRIPT_CONTROL scrCtrl = {0};
SCRIPT_STATE scrState = {0};
hr = ::ScriptItemize(pStr, nLn, cMaxItems, &scrCtrl, &scrState, pItems, &cItems);
if(SUCCEEDED(hr))
{
FormatAdd2(str, L"cItems=%d: ", cItems);
int nCntGlyphs = nLn * 4;
WORD* pGlyphs = new WORD[nCntGlyphs];
WORD* pLogClust = new WORD[nLn];
SCRIPT_VISATTR* pSVs = new SCRIPT_VISATTR[nCntGlyphs];
//Go through each run
for(int i = 0; i < cItems; i++)
{
FormatAdd2(str, L"[%d]:", i);
SCRIPT_CACHE sc = NULL;
int nCntGlyphsWrtn = 0;
int iPos = pItems[i].iCharPos;
const WCHAR* pP = &pStr[iPos];
int cChars = i + 1 < cItems ? pItems[i + 1].iCharPos - iPos : nLn - iPos;
hr = ::ScriptShape(hDc, &sc, pP, cChars,
nCntGlyphs, &pItems[i].a, pGlyphs, pLogClust, pSVs, &nCntGlyphsWrtn);
if(SUCCEEDED(hr))
{
std::wstring strGlyphs;
for(int g = 0; g < nCntGlyphsWrtn; g++)
{
FormatAdd2(strGlyphs, L"%02X,", pGlyphs[g]);
}
std::wstring strLogClust;
for(int w = 0; w < cChars; w++)
{
FormatAdd2(strLogClust, L"%02X,", pLogClust[w]);
}
std::wstring strSVs;
for(int g = 0; g < nCntGlyphsWrtn; g++)
{
FormatAdd2(strSVs, L"%02X,", pSVs[g]);
}
FormatAdd2(str, L"c=%d {G:%s LC:%s SV:%s} ", nCntGlyphsWrtn, strGlyphs.c_str(), strLogClust.c_str(), strSVs.c_str());
int* pAdvances = new int[nCntGlyphsWrtn];
GOFFSET* pOffsets = new GOFFSET[nCntGlyphsWrtn];
ABC abc = {0};
hr = ::ScriptPlace(hDc, &sc, pGlyphs, nCntGlyphsWrtn, pSVs, &pItems[i].a, pAdvances, pOffsets, &abc);
if(SUCCEEDED(hr))
{
std::wstring strAdvs;
for(int g = 0; g < nCntGlyphsWrtn; g++)
{
FormatAdd2(strAdvs, L"%02X,", pAdvances[g]);
}
std::wstring strOffs;
for(int g = 0; g < nCntGlyphsWrtn; g++)
{
FormatAdd2(strOffs, L"u=%02X v=%02X,", pOffsets[g].du, pOffsets[g].dv);
}
FormatAdd2(str, L"{a=%d,b=%d,c=%d} {A:%s OF:%s}", abc.abcA, abc.abcB, abc.abcC, strAdvs.c_str(), strOffs.c_str());
}
delete[] pAdvances;
delete[] pOffsets;
}
//Clear cache
hr = ::ScriptFreeCache(&sc);
assert(SUCCEEDED(hr));
}
delete[] pSVs;
delete[] pGlyphs;
delete[] pLogClust;
}
}
hr = ::ScriptStringFree(&ssa);
assert(SUCCEEDED(hr));
}
}
std::wstring& FormatAdd2(std::wstring& str, LPCTSTR pszFormat, ...)
{
va_list argList;
va_start(argList, pszFormat);
int nSz = _vsctprintf(pszFormat, argList) + 1;
TCHAR* pBuff = new TCHAR[nSz]; //One char for last null
pBuff[0] = 0;
_vstprintf_s(pBuff, nSz, pszFormat, argList);
pBuff[nSz - 1] = 0;
str.append(pBuff);
delete[] pBuff;
va_end(argList);
return str;
}
编辑:我已经能够创建一个演示GUI应用程序,展示了Barmak Shemirani下面提出的解决方案。