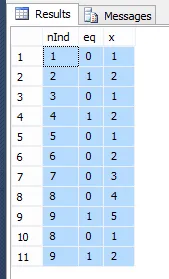
我试图生成“x”列中的数字,考虑到“eq”字段中的值。它应该为每个记录分配一个数字,直到遇到值“1”,下一行应重新开始计数。我尝试过使用
row_number,但问题是我需要评估的列中只有1和0,并且我见过的使用row_number的情况都是在一个列中不断增长的值。我还尝试过使用rank,但我没有成功使其工作。nInd Fecha Tipo @Inicio @contador_I @Final @contador_F eq x
1 18/03/2002 I 18/03/2002 1 null null 0 1
2 20/07/2002 F 18/03/2002 1 20/07/2002 1 1 2
3 19/08/2002 I 19/08/2002 2 20/07/2002 1 0 1
4 21/12/2002 F 19/08/2002 2 21/12/2002 2 1 2
5 17/03/2003 I 17/03/2003 3 21/12/2002 2 0 1
6 01/04/2003 I 17/03/2003 4 21/12/2002 2 0 2
7 07/04/2003 I 17/03/2003 5 21/12/2002 2 0 3
8 02/06/2003 F 17/03/2003 5 02/06/2003 3 0 4
9 31/07/2003 F 17/03/2003 5 31/07/2003 4 0 5
10 31/08/2003 F 17/03/2003 5 31/08/2003 5 1 6
11 01/09/2005 I 01/09/2005 6 31/08/2003 5 0 1
12 05/09/2005 I 01/09/2005 7 31/08/2003 5 0 2
13 31/12/2005 F 01/09/2005 7 31/12/2005 6 0 3
14 14/01/2006 F 01/09/2005 7 14/01/2006 7 1 4