我有一个JSON文件存储在一个.txt文件中,我想将其加载到R中,但是出现了以下错误:
Error in feed_push_parser(readBin(con, raw(), n), reset = TRUE) :
parse error: trailing garbage
" : "SUCCESS" } /* 1 */ { "_id" : "b736c374-b8ae-4e9
(right here) ------^
我猜错误是由于多个实例的/* (数字) */,我无法手动删除所有这些实例,因为我的文件有10k个这样的实例。在将数据加载到R之前,是否有一种方法可以删除这样的实例?
我的JSON文件如下:
/* 0 */
{
"_id" : "93ccbdb6-8947",
"uiSearchRequest" : {
"travelDate" : 20151206,
"travelDuration" : 7,
"shopperDuration" : 30,
"oneWay" : false,
"userId" : "ATP1KKP",
"queryId" : "93ccbdb6-8947",
"subRequests" : [{
"origin" : "WAS",
"destination" : "LON",
"carrier" : "AA",
"fareClasses" : "",
"owrt" : "1,2"
}]
},
"downloadCount" : 0,
"requestDate" : 20151205,
"totalRecords" : 0,
"status" : "SUCCESS"
}
/* 1 */
{
"_id" : "b736c374-b8ae",
"uiSearchRequest" : {
"travelDate" : 20151206,
"travelDuration" : 7,
"shopperDuration" : 30,
"oneWay" : false,
"userId" : "ATP1KKP",
"queryId" : "b736c374-b8ae",
"subRequests" : [{
"origin" : "WAS",
"destination" : "LON",
"carrier" : "AA",
"fareClasses" : "",
"owrt" : "1,2"
}]
},
"downloadCount" : 0,
"requestDate" : 20151205,
"totalRecords" : 0,
"status" : "SUCCESS"
}
/* 2 */
{
"_id" : "3312605f-8304",
"uiSearchRequest" : {
"travelDate" : 20151206,
"travelDuration" : 7,
"shopperDuration" : 30,
"oneWay" : false,
"userId" : "ATP1SXE",
"queryId" : "3312605f-8304",
"subRequests" : [{
"origin" : "LON",
"destination" : "IAD",
"carrier" : "AA",
"fareClasses" : "",
"owrt" : "1,2"
}]
},
"downloadCount" : 2,
"requestDate" : 20151205,
"totalRecords" : 0,
"status" : "SUCCESS"
}
/* 3 */
{
"_id" : "6b668cfa-9b79",
"uiSearchRequest" : {
"travelDate" : 20151206,
"travelDuration" : 7,
"shopperDuration" : 30,
"oneWay" : false,
"userId" : "ATP1NXA",
"queryId" : "6b668cfa-9b79",
"subRequests" : [{
"origin" : "WAS",
"destination" : "LON",
"carrier" : "AA",
"fareClasses" : "",
"owrt" : "1,2"
}]
},
"downloadCount" : 1,
"requestDate" : 20151205,
"totalRecords" : 1388,
"status" : "SUCCESS"
}
/* 4 */
{
"_id" : "41c373a1-e4cb",
"uiSearchRequest" : {
"travelDate" : 20151206,
"travelDuration" : 7,
"shopperDuration" : 30,
"oneWay" : false,
"userId" : "ATP6CXS",
"queryId" : "41c373a1-e4cb",
"subRequests" : [{
"origin" : "WAS",
"destination" : "LON",
"carrier" : "AA",
"fareClasses" : "",
"owrt" : "1,2"
}]
},
"downloadCount" : 0,
"requestDate" : 20151205,
"totalRecords" : 1388,
"status" : "SUCCESS"
}
/* 5 */
{
"_id" : "2c8331c4-21ca",
"uiSearchRequest" : {
"travelDate" : 20151206,
"travelDuration" : 7,
"shopperDuration" : 30,
"oneWay" : false,
"userId" : "ATP1KKP",
"queryId" : "2c8331c4-21ca",
"subRequests" : [{
"origin" : "WAS",
"destination" : "LON",
"carrier" : "AA",
"fareClasses" : "",
"owrt" : "1,2"
}]
},
"downloadCount" : 0,
"requestDate" : 20151205,
"totalRecords" : 1388,
"status" : "SUCCESS"
}
/* 6 */
{
"_id" : "71a09900-1c13",
"uiSearchRequest" : {
"travelDate" : 20151206,
"travelDuration" : 7,
"shopperDuration" : 30,
"oneWay" : false,
"userId" : "ATP6CXS",
"queryId" : "71a09900-1c13",
"subRequests" : [{
"origin" : "WAS",
"destination" : "LON",
"carrier" : "AF",
"fareClasses" : "",
"owrt" : "1,2"
}, {
"origin" : "WAS",
"destination" : "LON",
"carrier" : "AA",
"fareClasses" : "",
"owrt" : "1,2"
}, {
"origin" : "WAS",
"destination" : "LON",
"carrier" : "DL",
"fareClasses" : "",
"owrt" : "1,2"
}, {
"origin" : "WAS",
"destination" : "LON",
"carrier" : "LH",
"fareClasses" : "",
"owrt" : "1,2"
}, {
"origin" : "WAS",
"destination" : "LON",
"carrier" : "BA",
"fareClasses" : "",
"owrt" : "1,2"
}]
},
"downloadCount" : 0,
"requestDate" : 20151205,
"totalRecords" : 6941,
"status" : "SUCCESS"
}
/* 7 */
{
"_id" : "a036a42a-918b",
"uiSearchRequest" : {
"travelDate" : 20151206,
"travelDuration" : 7,
"shopperDuration" : 30,
"oneWay" : false,
"userId" : "ATP1MMM",
"queryId" : "a036a42a-918b",
"subRequests" : [{
"origin" : "WAS",
"destination" : "LON",
"carrier" : "AA",
"fareClasses" : "",
"owrt" : "1,2"
}]
},
"downloadCount" : 0,
"requestDate" : 20151205,
"totalRecords" : 1388,
"status" : "SUCCESS"
}
/* 8 */
{
"_id" : "c547be36-805c",
"uiSearchRequest" : {
"travelDate" : 20151206,
"travelDuration" : 7,
"shopperDuration" : 30,
"oneWay" : false,
"userId" : "ATP1SXB",
"queryId" : "c547be36-805c",
"subRequests" : [{
"origin" : "CHI",
"destination" : "LON",
"carrier" : "BA",
"fareClasses" : "",
"owrt" : "1,2"
}]
},
"downloadCount" : 2,
"requestDate" : 20151205,
"totalRecords" : 1072,
"status" : "SUCCESS"
}
以下是我的代码(虽然我还没有实现很多):
library(jsonlite)
library(RJSONIO)
json_data_raw<-fromJSON("mydata.txt")
json_file <- lapply(json_data_raw, function(x) {
x[sapply(x, is.null)] <- NA
unlist(x)
})
output <-- do.call("rbind", json_file)
write.csv(a, file="json.csv",row.names = FALSE)
file.show("json.csv")
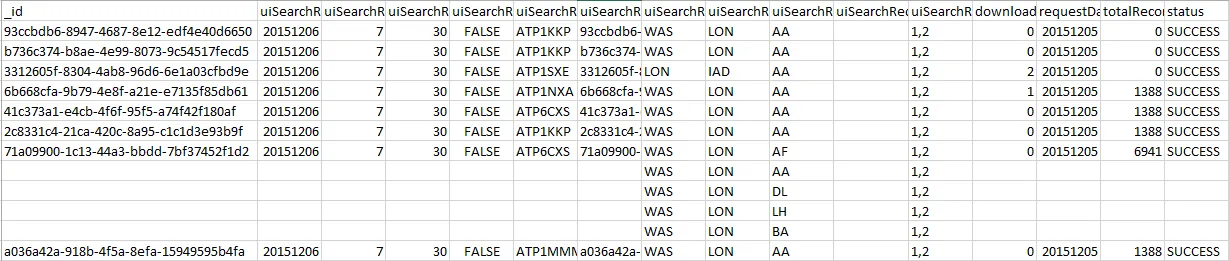
我正在尝试将我的输出保存为以下的CSV文件格式:
请注意,其中包含HTML标签。
fromJSON(grep('/\\*.*\\*/', readLines(mydata.txt), invert = TRUE, value = TRUE))去除注释行,但对我仍然失败。 - alistaire