“GIT让我感到非常困惑!”
“您似乎来自于集中式版本控制系统的背景,并表现出Joel在
here中所描述的知识诅咒的症状。您只需要接受Git分布式的本质,一切很快就会变得清晰明了。
:)”
“Pro Git书中以下内容是一个好的起点,可以帮助您提高理解:
http://git-scm.com/book/en/Getting-Started-About-Version-Control。”
“我应该在我的笔记本电脑上创建一个个人仓库,然后将其推送或克隆到网络驱动器上的新中央仓库。这样做是否正确?”
“Git本身并不对此作出任何规定,但是是的,这是一个被广泛使用的合理设置。”
“这是通过推送还是克隆完成的?”
“
推送意味着将您本地分支中的本地更改发送到位于另一个仓库中的某个分支,称为“远程仓库”。”
这个术语有些令人困惑,因为所谓的远程 repo 实际上可以位于与“你的存储库”相同的机器上。“远程”是 Git 中一个相对而非绝对的术语。应该将“远程存储库”理解为本地存储库知道的其他存储库。
克隆大致意味着获取远程存储库的本地副本(成为“你的存储库”)。
额外奖励:拉取意味着将某个远程存储库中存在的所有更改“下载”到“你的存储库”中。
你需要在网络驱动器上创建/初始化一个存储库,然后设置本地存储库,以便可以与其通信(推送、拉取等)。
我正在使用 GIT-Extensions,他们对于中央存储库有这样的说法:[...]
我认为 Git-Extensions 帮助文档中的这一段文字是误导性的。你认为的“中央”存储库可以是“裸”的(即仅包含版本历史,没有任何工作副本),但不一定是。
那么这听起来对我来说就像一个普通的 SVN 存储库?
Git是一种分布式的工具,这意味着所有的存储库都处于平等地位;没有必要有任何一个存储库比其他存储库更重要或更为中心。也就是说,你可以将某个特定的存储库视为中央/规范存储库。这是Git和集中式版本控制系统(如SVN)之间的主要区别之一。
“您的存储库”中发生的事情由您决定。如果您愿意,可以从另一个存储库获取更改或向其发送更改(假设您拥有对其的写访问权限),但后者不能从“您的存储库”获取任何内容,也不能强制执行任何操作,除非您明确要求……当然,除非控制该远程存储库的人对您的存储库有写访问权限。
但如果是这样的话,那么根据此答案中的图表:
What are the differences between "git commit" and "git push"?,我的两个存储库会是什么?它们是工作区和本地存储库,还是本地和远程存储库?
虽然我觉得这个描述有点误导,但你可以初步考虑每个存储库由三个区域组成(参见http://git-scm.com/book/en/Getting-Started-Git-Basics#The-Three-States)。
- 工作目录,或者更准确地说工作树(在你链接的图表中称为“工作区”)。广义上讲,它对应于你检出的副本,即坐落在文件系统中你项目树形结构中的文件体。
- 存储快照/提交的地方,在《Pro Git》书中被称为“Git目录”,但我不是这个术语的铁粉。你可以将此区域看作是一个专门用于记录项目历史的相册。
- 索引或暂存区是工作树和“存储快照/提交的地方”之间的中间层。请参阅在 Git 中“添加到索引”真正意味着什么?
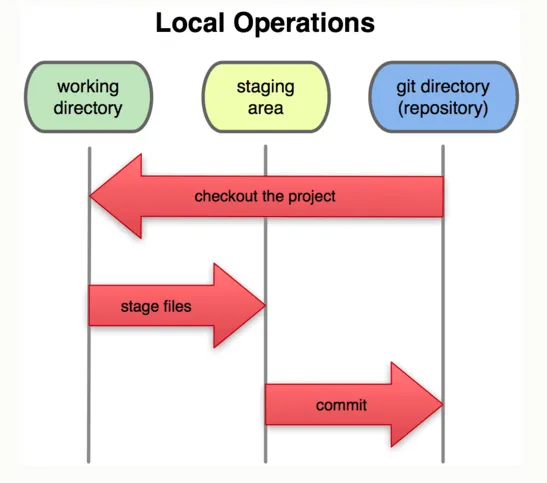
在
你提供的图表上,
工作区、
索引和
仓库是指“你的仓库”的三种状态;远程仓库的三种状态未显示;远程仓库只被描述为一个黑匣子。
这是否决定了我应该提交和检出还是推送和拉取?
提交和
检出是完全局限于“你的仓库”的操作。
- 提交意味着对你的项目进行快照并将其存储在仓库中;此操作与从暂存区到“快照存储位置”传输数据相关。
- 检出意味着获取现有快照的副本到你的工作树中,以便查看和处理它,并可能使你的代码朝完全不同的方向发展。
推送和
获取则意味着在“你的仓库”和某个远程仓库之间进行数据传输,但是方向相反:
- 推送:将“你的仓库”-->远程仓库
- 获取:将“你的仓库”<--远程仓库
拉取是指获取并自动集成从远程仓库获取的更改到“你的仓库”中。
git remote add<remote-name> <url-of-remote-repo>。之后,在您的本地存储库中,您将能够向网络驱动器上的远程存储库推送(并且,如果需要,从其中获取)。 - jub0bs