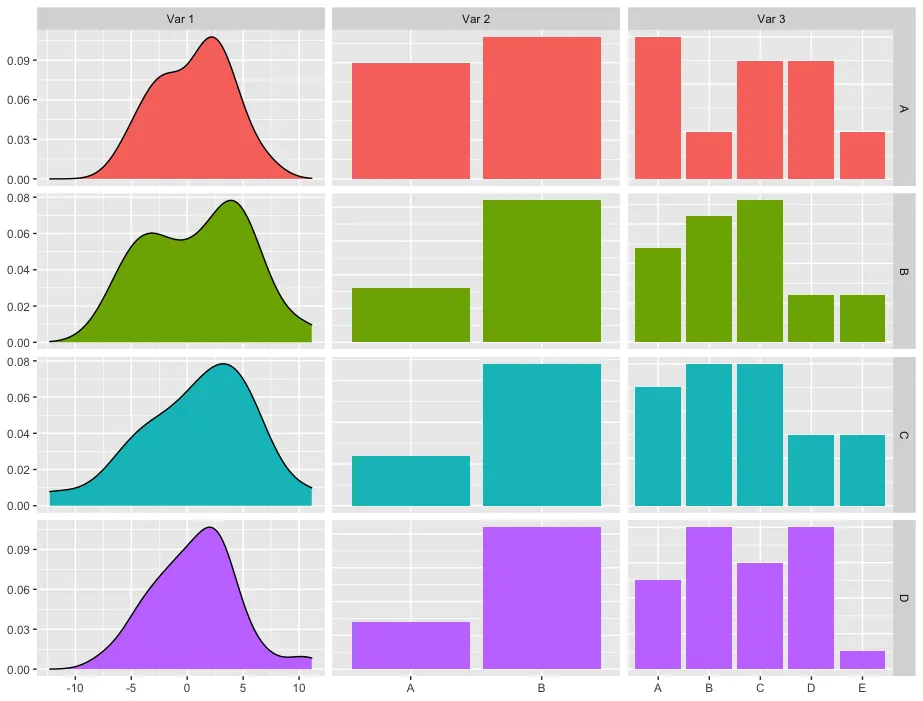
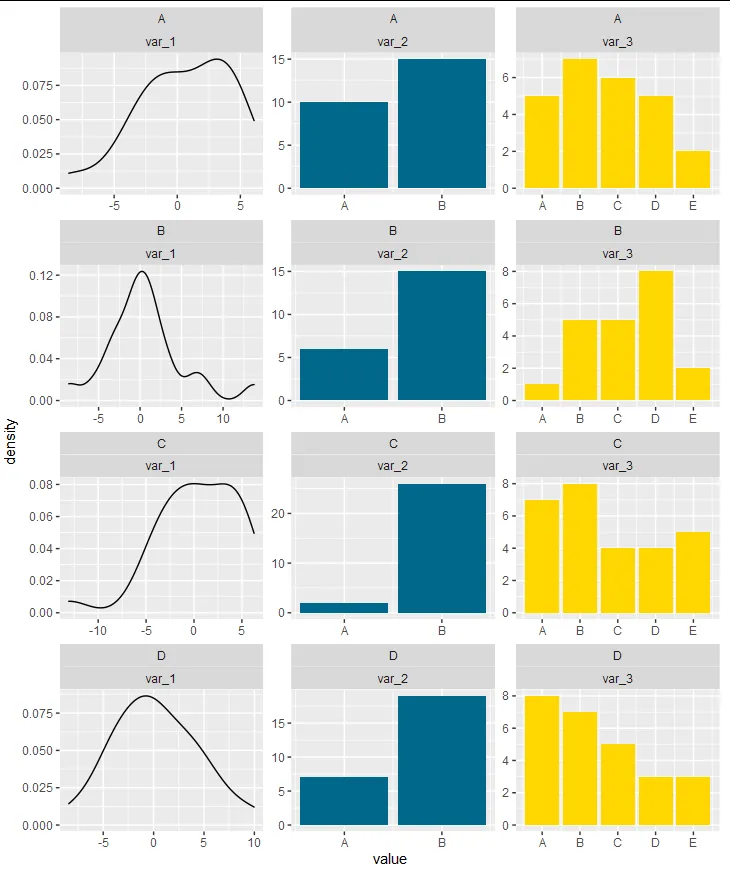
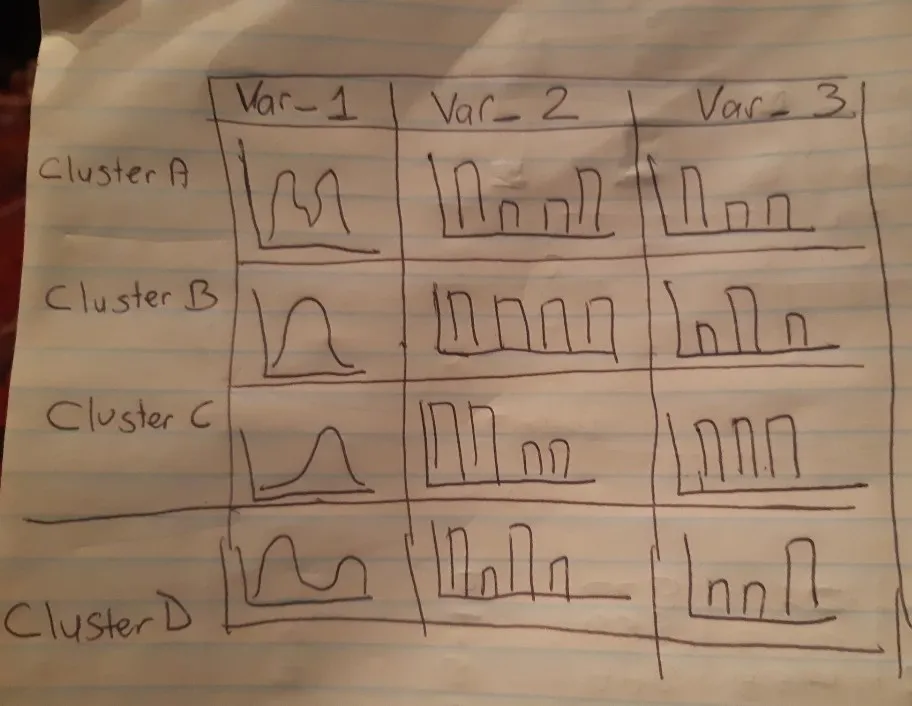
我正在尝试制作一系列类似于这样的图表:
我有一些混合分类和连续数据。当只有分类变量或只有连续变量时,我能够制作这一系列图表。但是当两种类型的变量同时存在时,我无法生成这一系列图表。
我已经创建了一些数据。请问是否有一种方法可以调试此代码,以便产生一系列图表?
library(ggplot2)
library(gridExtra)
library(tidyr)
/create some data/
var_1 <- rnorm(100,1,4)
var_2 <- sample( LETTERS[1:2], 100, replace=TRUE, prob=c(0.3, 0.7) )
var_3 <- sample( LETTERS[1:5], 100, replace=TRUE, prob=c(0.2, 0.2,0.2,0.2, 0.1) )
cluster <- sample( LETTERS[1:4], 100, replace=TRUE, prob=c(2.5, 2.5, 2.5, 2.5) )
/put in a frame/
f <- data.frame(var_1, var_2, var_3, cluster)
/convert to factors/
f$var_2 = as.factor(f$var_2)
f$var_3 = as.factor(f$var_3)
f$cluster = as.factor(f$cluster)
/create graphs/
f2 %>% pivot_longer(cols = contains("var"), names_to = "variable") %>%
ggplot(aes(x = value, fill = value)) +
geom_bar() + geom_density() +
facet_grid(rows = vars(cluster),
cols = vars(variable),
scales = "free") +
labs(y = "freq", fill = "Var")
当我只有分类变量时,以下代码可以使用:
var_2 <- sample( LETTERS[1:2], 100, replace=TRUE, prob=c(0.3, 0.7) )
var_3 <- sample( LETTERS[1:5], 100, replace=TRUE, prob=c(0.2, 0.2,0.2,0.2, 0.1) )
cluster <- sample( LETTERS[1:4], 100, replace=TRUE, prob=c(2.5, 2.5, 2.5, 2.5) )
f <- data.frame(var_2, var_3, cluster)
f$var_2 = as.factor(f$var_2)
f$var_3 = as.factor(f$var_3)
f$cluster = as.factor(f$cluster)
f%>% pivot_longer(cols = contains("var"), names_to = "variable") %>% ggplot(aes(x = value, fill = value)) + geom_bar() + geom_density() +facet_grid(rows = vars(cluster), cols = vars(variable), scales = "free") + labs(y = "freq", fill = "Var")