我已经创建了一个 TreeNode 类的方法,希望它返回一个树的中序遍历的平铺列表。
我的示例树如下图所示: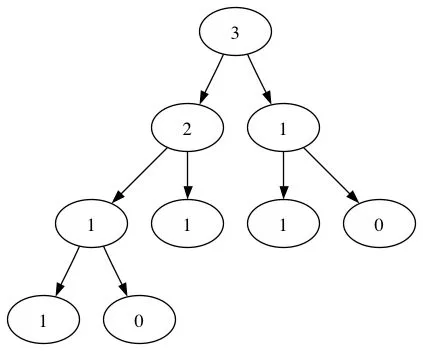 中序遍历输出应为:[1, 1, 0, 2, 1, 3, 1, 1, 0],但我得到的是:[2, 1, 1, 0, 1, 3, 1, 1, 0]。
中序遍历输出应为:[1, 1, 0, 2, 1, 3, 1, 1, 0],但我得到的是:[2, 1, 1, 0, 1, 3, 1, 1, 0]。
以下是我的代码:
我的示例树如下图所示:
中序遍历输出应为:[1, 1, 0, 2, 1, 3, 1, 1, 0],但我得到的是:[2, 1, 1, 0, 1, 3, 1, 1, 0]。以下是我的代码:
def in_order_list(self, r = []):
hasLeft = self.left is not None
hasRight = self.right is not None
if self is None:
return
else:
if hasLeft:
self.left.in_order_list(r)
r.append(self.value)
if hasRight:
self.right.in_order_list(r)
return r
有人能给我一些提示为什么会发生这种情况吗?
谢谢 Alex