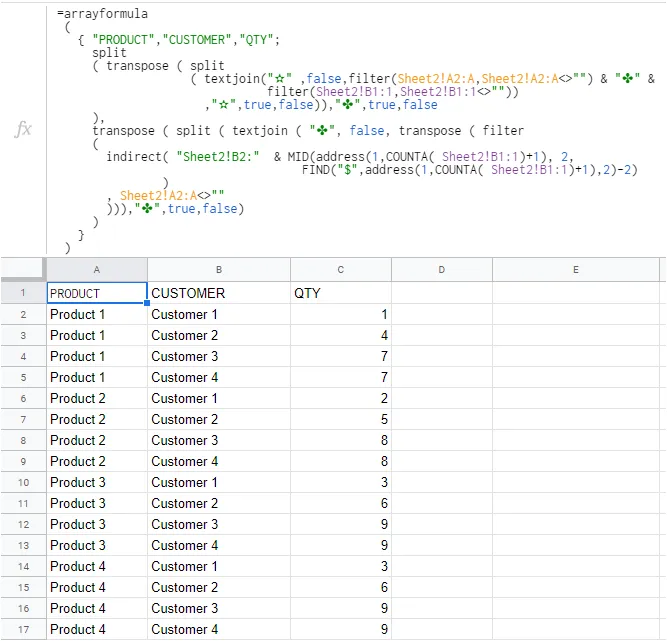
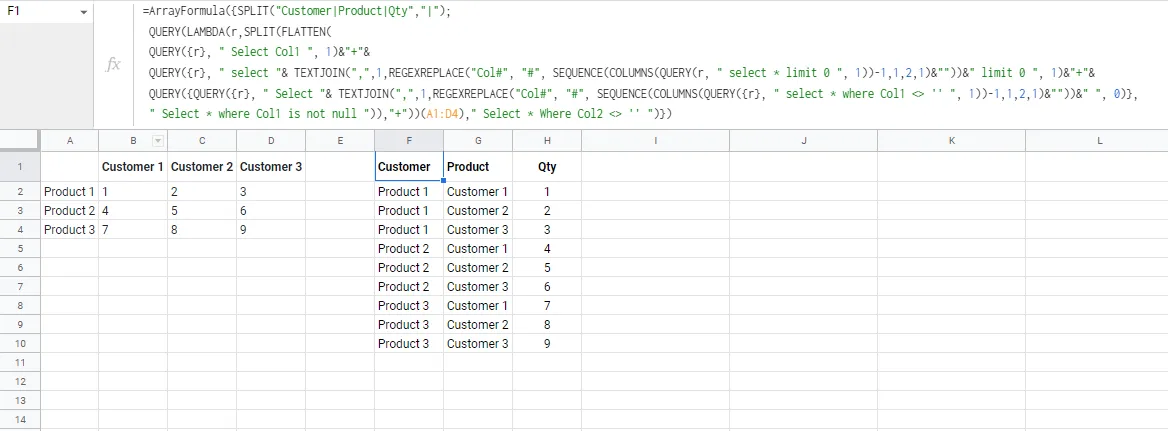
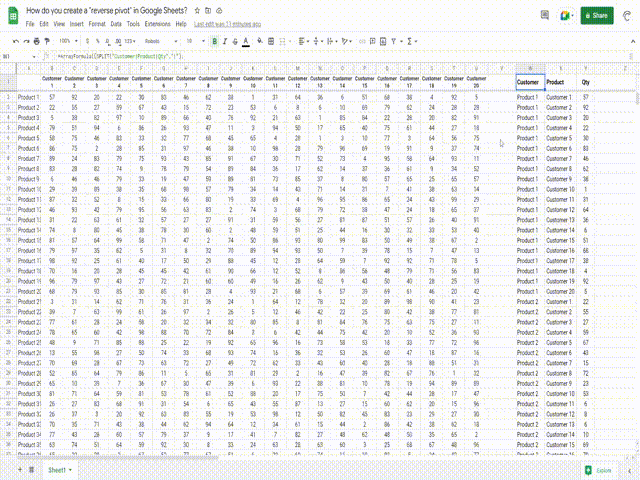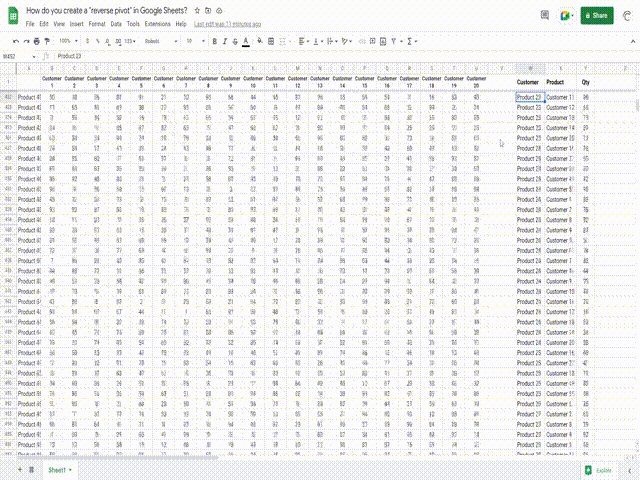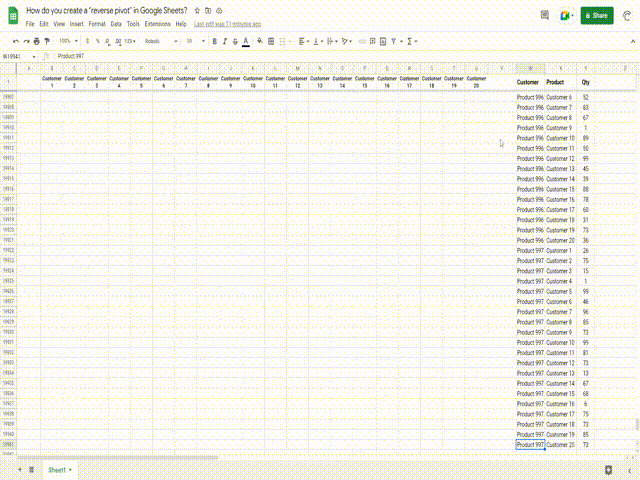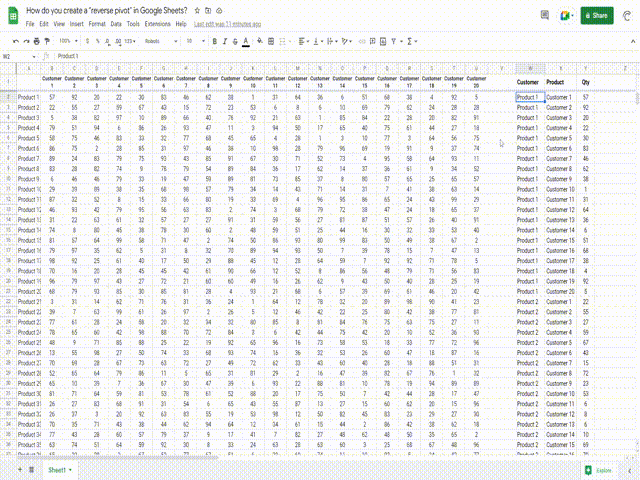
我正在尝试创建一个“逆数据透视表”函数。我已经搜索了很长时间,但找不到现成的函数。
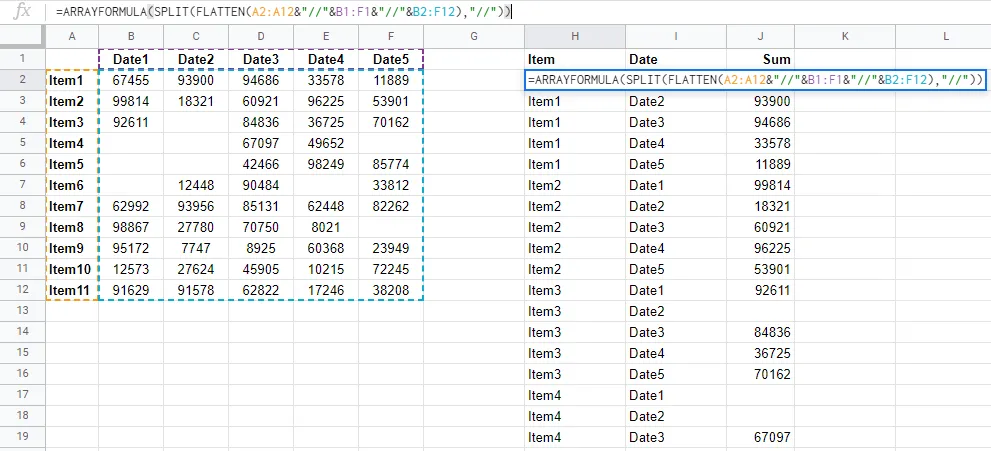
我有一个摘要表格,其中包含多达20列和数百行数据,然而我想将其转换为一个扁平列表,以便可以导入到数据库(或者使用扁平数据创建更多的数据透视表!)
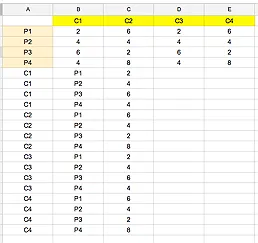
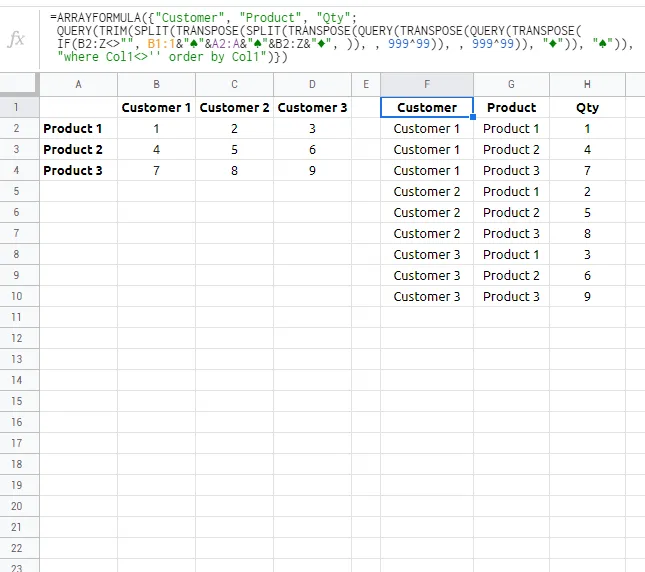
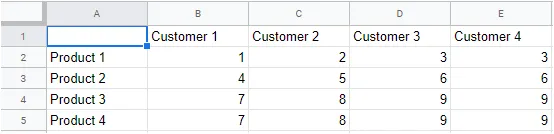
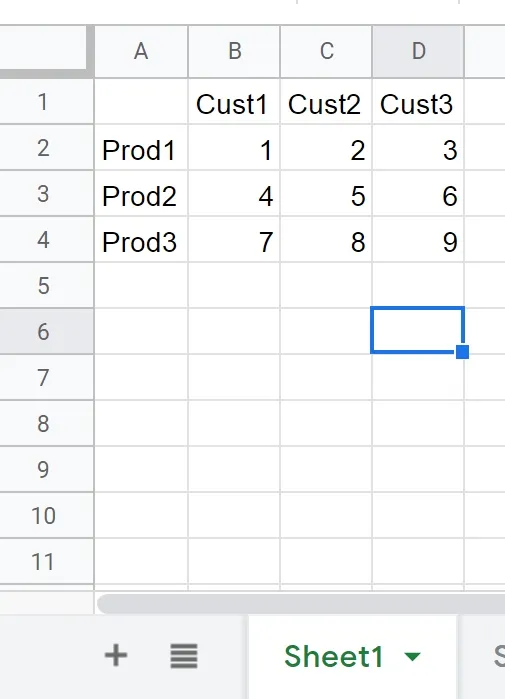
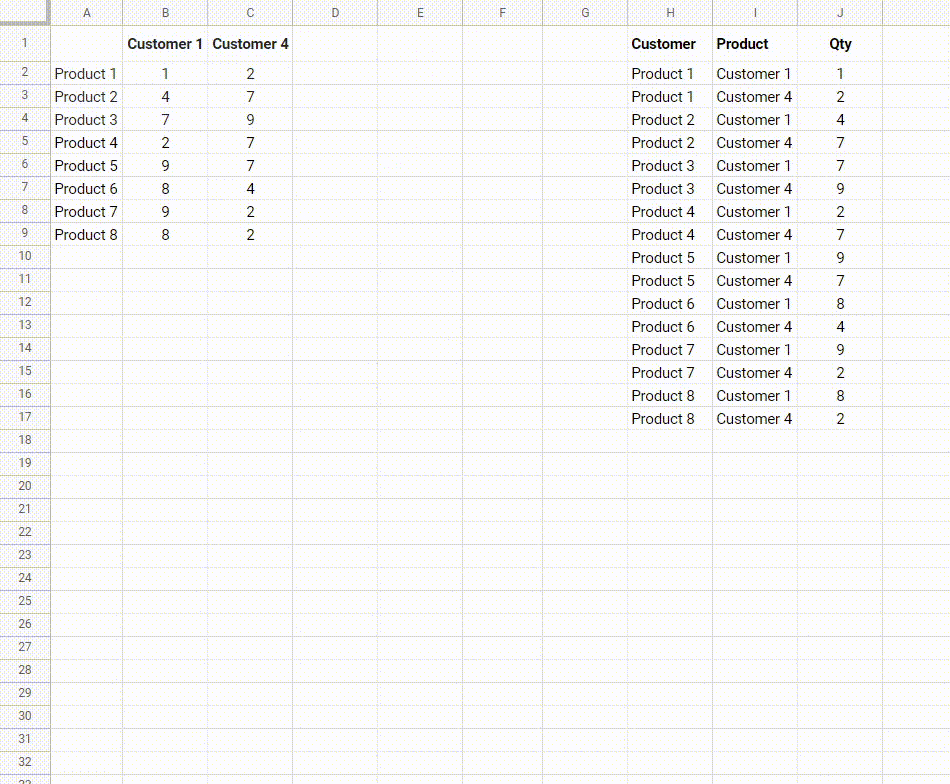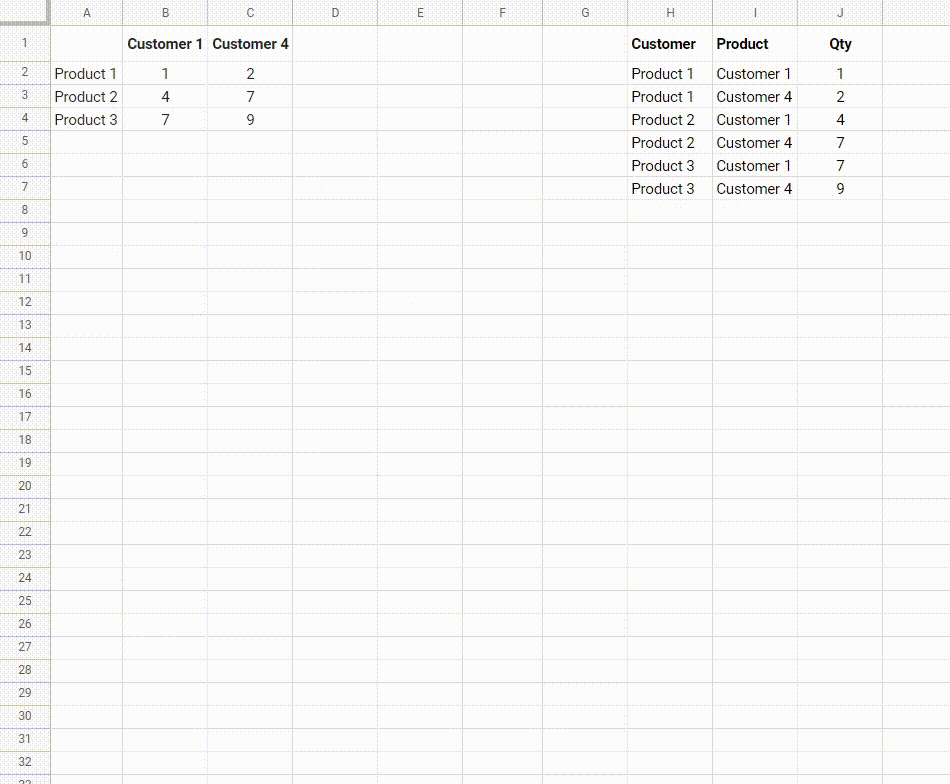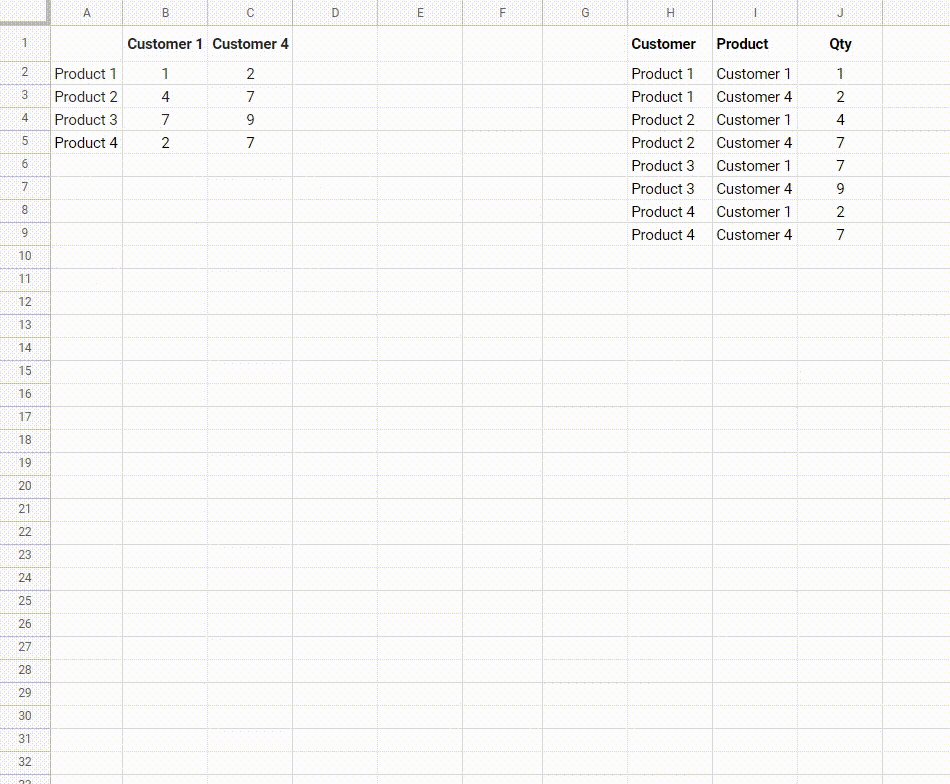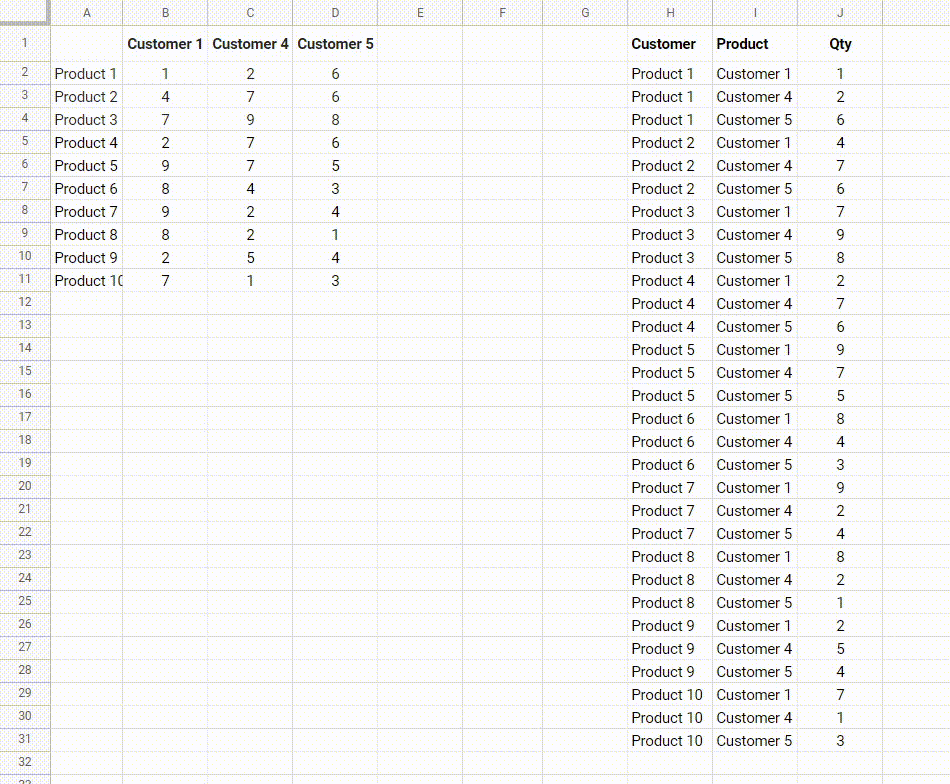
因此,我的数据格式如下:
| 客户1 | 客户2 | 客户3 | |
|---|---|---|---|
| 产品1 | 1 | 2 | 3 |
| 产品2 | 4 | 5 | 6 |
| 产品3 | 7 | 8 | 9 |
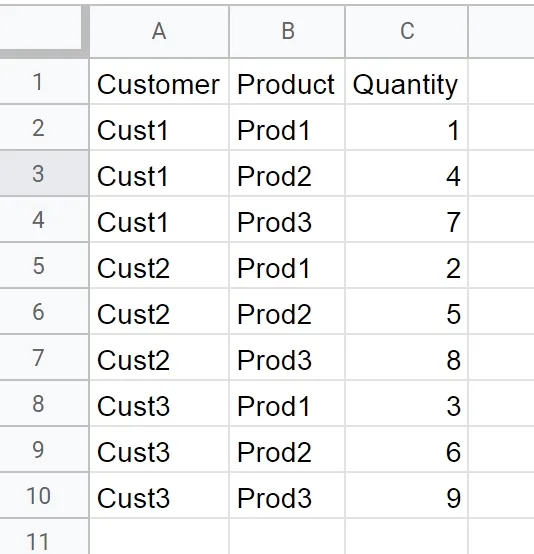
需要将其转换为以下格式:
Customer | Product | Qty
-----------+-----------+----
Customer 1 | Product 1 | 1
Customer 1 | Product 2 | 4
Customer 1 | Product 3 | 7
Customer 2 | Product 1 | 2
Customer 2 | Product 2 | 5
Customer 2 | Product 3 | 8
Customer 3 | Product 1 | 3
Customer 3 | Product 2 | 6
Customer 3 | Product 3 | 9
sheet1范围内的内容,并将重新格式化的行添加到同一工作表的底部。但是我想让它能在sheet2上运行,以读取来自sheet1的整个范围。无论我尝试什么,都似乎无法使其正常工作,想知道是否有人能给我任何提示?以下是我到目前为止的代码:function readRows() {
var sheet = SpreadsheetApp.getActiveSheet();
var rows = sheet.getDataRange();
var numRows = rows.getNumRows();
var values = rows.getValues();
heads = values[0]
for (var i = 1; i <= numRows - 1; i++) {
for (var j = 1; j <= values[0].length - 1; j++) {
var row = [values[i][0], values[0][j], values[i][j]];
sheet.appendRow(row)
}
}
};