根据Python的GIL,我们不能在CPU绑定进程中使用线程,那么我的问题是,Apache Spark如何在多核环境下利用Python?
1个回答
11
Python中的多线程问题与Apache Spark内部机制是分开处理的。Spark上的并行处理在JVM内部进行。
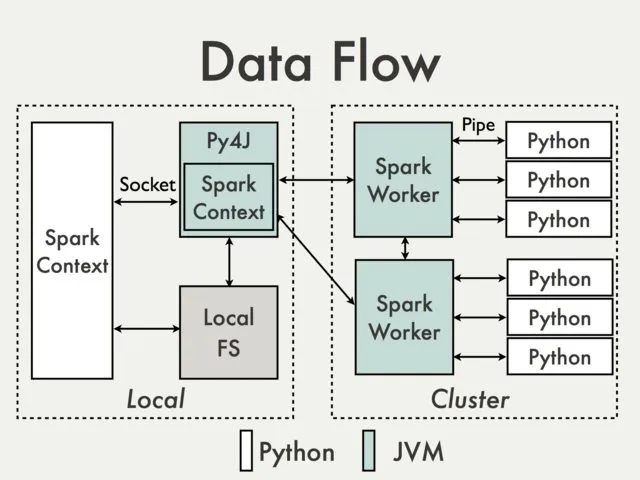
这是因为在Python驱动程序中,SparkContext使用Py4J启动JVM并创建JavaSparkContext。
Py4J仅用于驱动程序本地通信,将Python和Java SparkContext对象连接起来;大数据传输则通过另一种机制执行。
Python中的RDD转换映射到Java中的PythonRDD对象上的转换。在远程工作机器上,PythonRDD对象会启动Python子进程,并使用管道与它们进行通信,发送用户代码和要处理的数据。
PS:我不确定这是否完全回答了您的问题。
- eliasah
9
3这里的主要观点是PySpark不使用多线程,所以GIL并不是一个问题。 - zero323
除了测试之外,PySpark仅在启动外部进程等执行某些次要任务的少数地方使用线程。其他所有操作都是良好的单线程处理。 - zero323
我同意@zero323的观点,这就是为什么我说所有并行处理都在JVM内部处理。 - eliasah
1@eliasah 说实话,JVM部分在多线程方面并不那么重要,你不觉得吗?为了清理和管理,需要多个线程,而JVM执行器也使用线程,但实际上,在Spark中并不一定需要实现并行性。可以在每台机器上启动相同数量的工作进程,以获得相同的并行性,尽管代价更高。 - zero323
谢谢您的评论@ravimalhotra,但我不确定它与我的答案有什么关系... - eliasah
显示剩余4条评论
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接