我正在尝试复现这篇论文的结果:https://arxiv.org/pdf/1607.06520.pdf
具体来说,是这个部分:
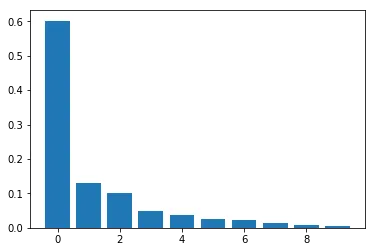
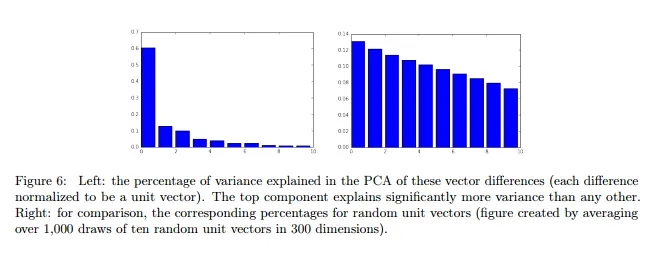
为了确定性别子空间,我们取了十个性别对差向量并计算其主成分(PCs)。如图6所示,有一个方向能够解释这些向量中大部分的变化。第一个特征值明显比其他的大。
我使用与作者相同的词向量集(Google News Corpus,300维),将其加载到word2vec中。
作者所指的“十个性别对差向量”是从以下单词对计算出来的:

我已按以下方式计算每个标准化向量之间的差异:
model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-
negative300.bin', binary = True)
model.init_sims()
pairs = [('she', 'he'),
('her', 'his'),
('woman', 'man'),
('Mary', 'John'),
('herself', 'himself'),
('daughter', 'son'),
('mother', 'father'),
('gal', 'guy'),
('girl', 'boy'),
('female', 'male')]
difference_matrix = np.array([model.word_vec(a[0], use_norm=True) - model.word_vec(a[1], use_norm=True) for a in pairs])
接下来我将按照论文中的做法,对得出的矩阵进行PCA处理,并选择10个主成分:
from sklearn.decomposition import PCA
pca = PCA(n_components=10)
pca.fit(difference_matrix)
然而,当我查看pca.explained_variance_ratio_时,结果却截然不同:
However 当我查看 pca.explained_variance_ratio_ 时,结果却截然不同:
array([ 2.83391436e-01, 2.48616155e-01, 1.90642492e-01,
9.98411858e-02, 5.61260498e-02, 5.29706681e-02,
2.75670634e-02, 2.21957722e-02, 1.86491774e-02,
1.99108478e-32])
或者用图表呈现:
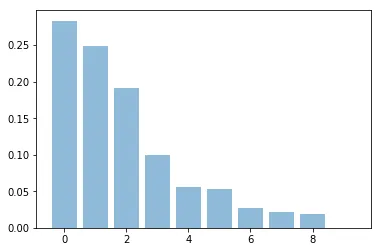
第一个成分解释的方差不到30%,但应该超过60%!
我的结果与随机选择向量时得到的结果类似,所以我一定做错了什么,但我找不出问题在哪里。
注意:我尝试过不对向量进行正规化,但是得到了相同的结果。