在Stroustrup的C++基础书籍中,他提供了一种纯面向对象的语言(第4页)。
class complex { double re, im; /* … */ };
complex a[ ] = { {1,2}, {3,4} };
他假设在纯面向对象语言中,
a 是分配在堆上的,并且 a 的内存布局如下所示:
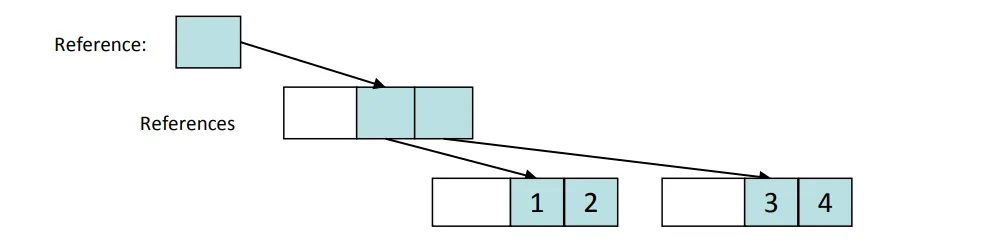 引用占一个字,堆开销占两个字,浮点数占四个字,据此估算出
引用占一个字,堆开销占两个字,浮点数占四个字,据此估算出 a 的大小为3*sizeof(reference)+3*sizeof(heap_overhead)+4*sizeof(double)。假设引用占一个字,堆开销占两个字,则得到一个可能的大小为19个字,与 C++ 的 8 个字进行比较。这种内存开销会带来运行时开销,因为要对元素进行间接访问和分配。这种间接访问通常会导致缓存利用问题,并限制 ROM 可能性。我注意到最上面的引用没有堆开销(白色矩形)。
我猜这是一般现象,而不是针对纯 OO 示例语言指定的。
但我找不到任何参考资料(我承认这不是一个搜索引擎友好的问题)。
更新
感谢您的回答。然而,我忘记发布我的原始猜测。(抱歉,这是我的错。)实际上,我也认为因为
a 本身可能被分配在堆栈或其他地方,它本身不会有堆开销。但后来,我注意到 BS 也说:“与“纯面向对象语言”中的更典型布局相比,每个用户定义的对象都单独分配在堆上并通过引用访问...”(第4页)。
所以,我认为他将实现限制为仅在堆上(或无堆栈)。
(当然,也许我对这个句子读得太多了。)