编辑:经过一些反馈,我创建了一个新的示例,应该更容易复现。
我正在用C++编写一个涉及大量链表迭代的项目。为了进行基准测试,我将代码重写成了Go。令人惊讶的是,即使在向clang++传递了-O标志后,我发现Go实现始终比C++实现快约10%。可能我只是在C++中缺少一些明显的优化,但我已经尝试了各种调整,并且一直在苦思冥想。
这里有一个简化版本,在C++和Go中具有相同的实现,其中Go程序运行得更快。它所做的就是创建一个带有3000个节点的链表,然后计算迭代此列表1,000,000次需要多长时间(在C++中为7.5秒,在Go中为6.8秒)。
C++:
#include <iostream>
#include <chrono>
using namespace std;
using ms = chrono::milliseconds;
struct Node {
Node *next;
double age;
};
// Global linked list of nodes
Node *nodes = nullptr;
void iterateAndPlace(double age) {
Node *node = nodes;
Node *prev = nullptr;
while (node != nullptr) {
// Just to make sure that age field is accessed
if (node->age > 99999) {
break;
}
prev = node;
node = node->next;
}
// Arbitrary action to make sure the compiler
// doesn't optimize away this function
prev->age = age;
}
int main() {
Node x = {};
std::cout << "Size of struct: " << sizeof(x) << "\n"; // 16 bytes
// Fill in global linked list with 3000 dummy nodes
for (int i=0; i<3000; i++) {
Node* newNode = new Node;
newNode->age = 0.0;
newNode->next = nodes;
nodes = newNode;
}
auto start = chrono::steady_clock::now();
for (int i=0; i<1000000; i++) {
iterateAndPlace(100.1);
}
auto end = chrono::steady_clock::now();
auto diff = end - start;
std::cout << "Elapsed time is : "<< chrono::duration_cast<ms>(diff).count()<<" ms "<<endl;
}
Go:
package main
import (
"time"
"fmt"
"unsafe"
)
type Node struct {
next *Node
age float64
}
var nodes *Node = nil
func iterateAndPlace(age float64) {
node := nodes
var prev *Node = nil
for node != nil {
if node.age > 99999 {
break
}
prev = node
node = node.next
}
prev.age = age
}
func main() {
x := Node{}
fmt.Printf("Size of struct: %d\n", unsafe.Sizeof(x)) // 16 bytes
for i := 0; i < 3000; i++ {
newNode := new(Node)
newNode.next = nodes
nodes = newNode
}
start := time.Now()
for i := 0; i < 1000000; i++ {
iterateAndPlace(100.1)
}
fmt.Printf("Time elapsed: %s\n", time.Since(start))
}
我的Mac的输出:
$ go run minimal.go
Size of struct: 16
Time elapsed: 6.865176895s
$ clang++ -std=c++11 -stdlib=libc++ minimal.cpp -O3; ./a.out
Size of struct: 16
Elapsed time is : 7524 ms
Clang版本:
$ clang++ --version
Apple LLVM version 8.0.0 (clang-800.0.42.1)
Target: x86_64-apple-darwin15.6.0
Thread model: posix
编辑: UKMonkey提出节点在Go中可能是连续分配的,但在C ++中不一定。为了测试这一点,我使用向量在C++中进行了连续分配,但这并未改变运行时间:
// Fill in global linked list with 3000 contiguous dummy nodes
vector<Node> vec;
vec.reserve(3000);
for (int i=0; i<3000; i++) {
vec.push_back(Node());
}
nodes = &vec[0];
Node *curr = &vec[0];
for (int i=1; i<3000; i++) {
curr->next = &vec[i];
curr = curr->next;
curr->age = 0.0;
}
我检查了结果链表确实是连续的:
std::cout << &nodes << " " << &nodes->next << " " << &nodes->next->next << " " << &nodes->next->next->next << "\n";
0x1032de0e0 0x7fb934001000 0x7fb934001010 0x7fb934001020
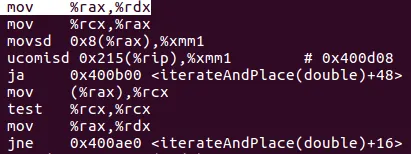
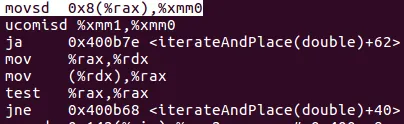
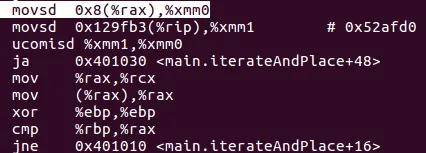
push rbp/pop rbp。有没有人成功地强制编译器内联迭代并放置函数?由于它被调用了 1,000,000 次,这可能会有所不同。 - kiloalphaindia__main后,我比较确定C++会生成迭代并放置代码的代码(可能是为了可以被其他代码调用),实际上会将其内联。代码在我的_main中,没有调用和堆栈推送。 - Crast