L2缓存在Kepler架构的GPU中如何处理引用局部性?例如,如果线程访问全局内存中的一个地址,假设该地址的值不在L2缓存中,那么该值如何被缓存?它是临时的吗?还是该地址附近的其他值也会被带到L2缓存中(空间)?
下面的图片来自NVIDIA白皮书。
下面的图片来自NVIDIA白皮书。
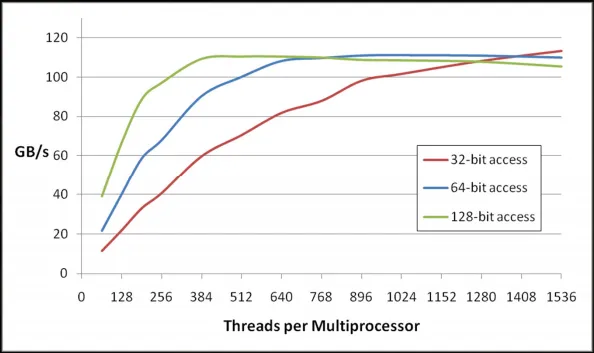
统一的L2高速缓存是从计算能力2.0及更高版本引入并继续在Kepler架构上得到支持。所采用的缓存策略是LRU(最近最少使用),其主要目的是避免全局内存带宽瓶颈。GPU应用程序可以表现出两种类型的局部性(时间和空间)。
每当尝试读取特定内存时,它会在高速缓存L1和L2中查找,如果未找到,则会从缓存行中加载128字节。这是默认模式。下图说明了为什么128位访问模式会得到良好结果。