我有一个查询(用于创建视图),它使用几个联接来获取每一列。对于每组添加的联接,性能会快速下降(指数级别?)。
如何使这个查询更快呢?请查看查询中的注释。
如果有帮助,这是使用WordPress DB模式。
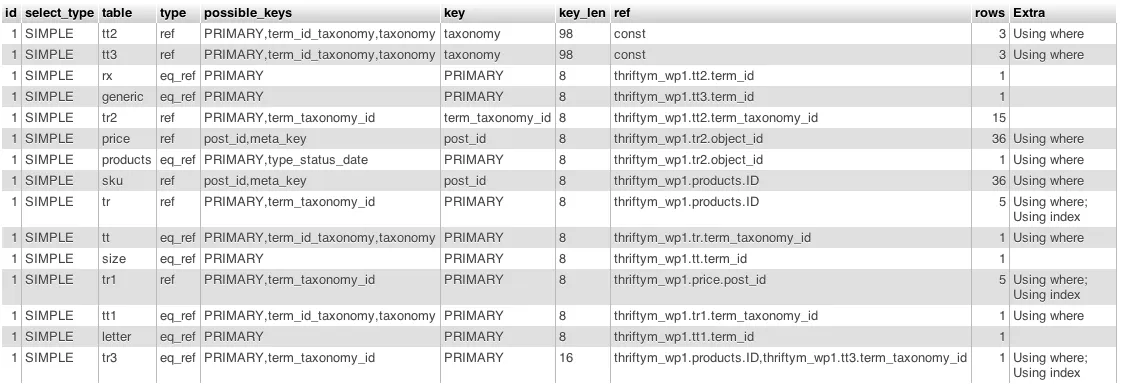
下面是 EXPLAIN 的截图
产品表
+--+----+
|id|name|
+--+----+
|1 |test|
+--+----+
元数据表
+----------+--------+-----+
|product_id|meta_key|value|
+----------+--------+-----+
|1 |price |9.99 |
+----------+--------+-----+
|1 |sku |ABC |
+----------+--------+-----+
TERM_RELATIONSHIPS表
+---------+----------------+
|object_id|term_taxonomy_id|
+---------+----------------+
|1 |1 |
+---------+----------------+
|1 |2 |
+---------+----------------+
分类术语表
+----------------+-------+--------+
|term_taxonomy_id|term_id|taxonomy|
+----------------+-------+--------+
|1 |1 |size |
+----------------+-------+--------+
|2 |2 |stock |
+----------------+-------+--------+
术语表
+-------+-----+
|term_id|name |
+-------+-----+
|1 |500mg|
+-------+-----+
|2 |10 |
+-------+-----+
查询
SELECT
products.id,
products.name,
price.value AS price,
sku.value AS sku,
size.name AS size
FROM products
/* These joins are performing quickly */
INNER JOIN `metadata` AS price ON products.id = price.product_id AND price.meta_key = 'price'
INNER JOIN `metadata` AS sku ON products.id = sku.product_id AND sku.meta_key = 'sku'
/* Here's the part that is really slowing it down - I run this chunk about 5 times with different strings to match */
INNER JOIN `term_relationships` AS tr ON products.id = tr.object_id
INNER JOIN `term_taxonomy` AS tt
ON tr.term_taxonomy_id = tt.term_taxonomy_id AND tt.taxonomy = 'size'
INNER JOIN `terms` AS size
ON tt.term_id = size.term_id
DESC tableName输出。 - Manu