我为你的问题添加了另一个答案:
引用:
我发布的CSV实际上是修改过的,我的原始CSV还包含每个骑手的列表,其中包含他们在每个阶段的得分。此列表看起来像这样[0, 40, 13, 0, 2, 55, 1, 17, 0, 14]。我正在尝试找到表现最好的团队。因此,我有一个由16名自行车手组成的团队,其中10名自行车手的得分计入每天的得分。然后将每天的得分相加以获得总得分。目的是尽可能提高这个最终总得分。
如果您认为我应该编辑我的第一篇帖子,请告诉我,因为我认为这样更清晰,因为我的第一篇帖子相当密集并回答了最初的问题。
让我们介绍一个新变量:
Zik = 1 if cyclist i is selected and is one of the top 10 in your team on day k
您需要将这些约束条件添加到链接变量Zik和Xi(如果自行车手i未被选中,即如果Xi = 0,则变量Zik不能等于1)中。
For all i, sum(Zik, 1<=k<=n_days) <= n_days * Xi
每天只能选出10名骑自行车的人,这是一种限制条件。
For all k, sum(Zik, 1<=i<=n_cyclists) <= 10
最后,您的目标可以写成这样:
Maximize sum(pik * Xi * Zik, 1<=i<=n_cyclists, 1 <= k <= n_days)
# where pik = nb_points of cyclist i at day k
这里是思考的部分。像这样写的目标并不是线性的(注意两个变量X和Z之间的乘法)。幸运的是,这里有二进制,并且有一个技巧可以将这个公式转换为其线性形式。
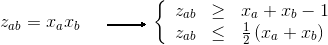
让我们引入新的变量Lik(
Lik = Xi * Zik),以线性化目标函数。
现在,目标函数可以写成以下形式,并且是线性的:
Maximize sum(pik * Lik, 1<=i<=n_cyclists, 1 <= k <= n_days)
# where pik = nb_points of cyclist i at day k
现在我们需要添加这些约束条件,使得
Lik等于
Xi * Zik:
For all i,k : Xi + Zik - 1 <= Lik
For all i,k : Lik <= 1/2 * (Xi + Zik)
“Voilà”是法语,意思是“瞧!”、“看这个!”。所以这句话的意思是:“瞧!这就是数学之美,你可以用线性方程来模拟很多东西。我介绍了一些高级概念,如果你一开始不理解也很正常。”
我在这个
文件中模拟了每天的得分列。
以下是解决新问题的Python代码:
import ast
from ortools.linear_solver import pywraplp
import pandas as pd
solver = pywraplp.Solver('cyclist', pywraplp.Solver.CBC_MIXED_INTEGER_PROGRAMMING)
cyclist_df = pd.read_csv('cyclists_day.csv')
cyclist_df['Punten_day'] = cyclist_df['Punten_day'].apply(ast.literal_eval)
variables_name = {}
variables_team = {}
variables_name_per_day = {}
variables_linear = {}
for _, row in cyclist_df.iterrows():
variables_name[row['Naam']] = solver.IntVar(0, 1, 'x_{}'.format(row['Naam']))
if row['Ploeg'] not in variables_team:
variables_team[row['Ploeg']] = solver.IntVar(0, solver.infinity(), 'y_{}'.format(row['Ploeg']))
for k in range(10):
variables_name_per_day[(row['Naam'], k)] = solver.IntVar(0, 1, 'z_{}_{}'.format(row['Naam'], k))
variables_linear[(row['Naam'], k)] = solver.IntVar(0, 1, 'l_{}_{}'.format(row['Naam'], k))
for team, var in variables_team.items():
constraint = solver.Constraint(0, solver.infinity())
constraint.SetCoefficient(var, 1)
for cyclist in cyclist_df[cyclist_df.Ploeg == team]['Naam']:
constraint.SetCoefficient(variables_name[cyclist], -1)
for team, var in variables_team.items():
constraint = solver.Constraint(0, 4)
constraint.SetCoefficient(var, 1)
constraint_max_cyclists = solver.Constraint(16, 16)
for cyclist in variables_name.values():
constraint_max_cyclists.SetCoefficient(cyclist, 1)
constraint_max_cost = solver.Constraint(0, 100)
for _, row in cyclist_df.iterrows():
constraint_max_cost.SetCoefficient(variables_name[row['Naam']], row['Waarde'])
for name, cyclist in variables_name.items():
constraint_link_cyclist_day = solver.Constraint(-solver.infinity(), 0)
constraint_link_cyclist_day.SetCoefficient(cyclist, - 10)
for k in range(10):
constraint_link_cyclist_day.SetCoefficient(variables_name_per_day[name, k], 1)
for k in range(10):
constraint_cyclist_per_day = solver.Constraint(10, 10)
for name in cyclist_df.Naam:
constraint_cyclist_per_day.SetCoefficient(variables_name_per_day[name, k], 1)
for name, cyclist in variables_name.items():
for k in range(10):
constraint_linearization1 = solver.Constraint(-solver.infinity(), 1)
constraint_linearization2 = solver.Constraint(-solver.infinity(), 0)
constraint_linearization1.SetCoefficient(cyclist, 1)
constraint_linearization1.SetCoefficient(variables_name_per_day[name, k], 1)
constraint_linearization1.SetCoefficient(variables_linear[name, k], -1)
constraint_linearization2.SetCoefficient(cyclist, -1/2)
constraint_linearization2.SetCoefficient(variables_name_per_day[name, k], -1/2)
constraint_linearization2.SetCoefficient(variables_linear[name, k], 1)
objective = solver.Objective()
objective.SetMaximization()
for _, row in cyclist_df.iterrows():
for k in range(10):
objective.SetCoefficient(variables_linear[row['Naam'], k], row['Punten_day'][k])
solver.Solve()
chosen_cyclists = [key for key, variable in variables_name.items() if variable.solution_value() > 0.5]
print('\n'.join(chosen_cyclists))
for k in range(10):
print('\nDay {} :'.format(k + 1))
chosen_cyclists_day = [name for (name, day), variable in variables_name_per_day.items()
if (day == k and variable.solution_value() > 0.5)]
assert len(chosen_cyclists_day) == 10
assert all(chosen_cyclists_day[i] in chosen_cyclists for i in range(10))
print('\n'.join(chosen_cyclists_day))
这是结果:
你的团队:
SAGAN Peter
GROENEWEGEN Dylan
VIVIANI Elia
ALAPHILIPPE Julian
PINOT Thibaut
MATTHEWS Michael
TRENTIN Matteo
COLBRELLI Sonny
VAN AVERMAET Greg
STUYVEN Jasper
BENOOT Tiesj
CICCONE Giulio
TEUNISSEN Mike
HERRADA Jesús
MEURISSE Xandro
GRELLIER Fabien
每天选择的自行车骑手
Day 1 :
SAGAN Peter
VIVIANI Elia
ALAPHILIPPE Julian
MATTHEWS Michael
COLBRELLI Sonny
VAN AVERMAET Greg
STUYVEN Jasper
CICCONE Giulio
TEUNISSEN Mike
HERRADA Jesús
Day 2 :
SAGAN Peter
ALAPHILIPPE Julian
MATTHEWS Michael
TRENTIN Matteo
COLBRELLI Sonny
VAN AVERMAET Greg
STUYVEN Jasper
TEUNISSEN Mike
NIZZOLO Giacomo
MEURISSE Xandro
Day 3 :
SAGAN Peter
GROENEWEGEN Dylan
VIVIANI Elia
MATTHEWS Michael
TRENTIN Matteo
VAN AVERMAET Greg
STUYVEN Jasper
CICCONE Giulio
TEUNISSEN Mike
HERRADA Jesús
Day 4 :
SAGAN Peter
VIVIANI Elia
PINOT Thibaut
MATTHEWS Michael
TRENTIN Matteo
COLBRELLI Sonny
VAN AVERMAET Greg
STUYVEN Jasper
TEUNISSEN Mike
HERRADA Jesús
Day 5 :
SAGAN Peter
VIVIANI Elia
ALAPHILIPPE Julian
PINOT Thibaut
MATTHEWS Michael
TRENTIN Matteo
COLBRELLI Sonny
VAN AVERMAET Greg
CICCONE Giulio
HERRADA Jesús
Day 6 :
SAGAN Peter
GROENEWEGEN Dylan
VIVIANI Elia
ALAPHILIPPE Julian
MATTHEWS Michael
TRENTIN Matteo
COLBRELLI Sonny
STUYVEN Jasper
CICCONE Giulio
TEUNISSEN Mike
Day 7 :
SAGAN Peter
VIVIANI Elia
ALAPHILIPPE Julian
MATTHEWS Michael
COLBRELLI Sonny
VAN AVERMAET Greg
STUYVEN Jasper
TEUNISSEN Mike
HERRADA Jesús
MEURISSE Xandro
Day 8 :
SAGAN Peter
GROENEWEGEN Dylan
VIVIANI Elia
ALAPHILIPPE Julian
MATTHEWS Michael
STUYVEN Jasper
TEUNISSEN Mike
HERRADA Jesús
NIZZOLO Giacomo
MEURISSE Xandro
Day 9 :
SAGAN Peter
GROENEWEGEN Dylan
VIVIANI Elia
ALAPHILIPPE Julian
PINOT Thibaut
TRENTIN Matteo
COLBRELLI Sonny
VAN AVERMAET Greg
TEUNISSEN Mike
HERRADA Jesús
Day 10 :
SAGAN Peter
GROENEWEGEN Dylan
VIVIANI Elia
PINOT Thibaut
COLBRELLI Sonny
STUYVEN Jasper
CICCONE Giulio
TEUNISSEN Mike
HERRADA Jesús
NIZZOLO Giacomo
让我们比较答案1和答案2的结果
print(solver.Objective().Value()):
第一个模型得到
3738.0,第二个模型得到
3129.087388325567。第二个模型得到的值更低,因为您只选择了每个阶段的10名自行车手,而不是16名。
现在,如果保留第一个解决方案并使用新的评分方法,我们得到
3122.9477585307413
我们可以认为第一个模型已经足够好了:我们不需要引入新的变量/约束条件,模型保持简单,并且我们得到的解决方案几乎与复杂模型一样好。有时候不必完全精确,通过一些近似方法可以更轻松快速地解决模型。