我遇到了以下逻辑问题:
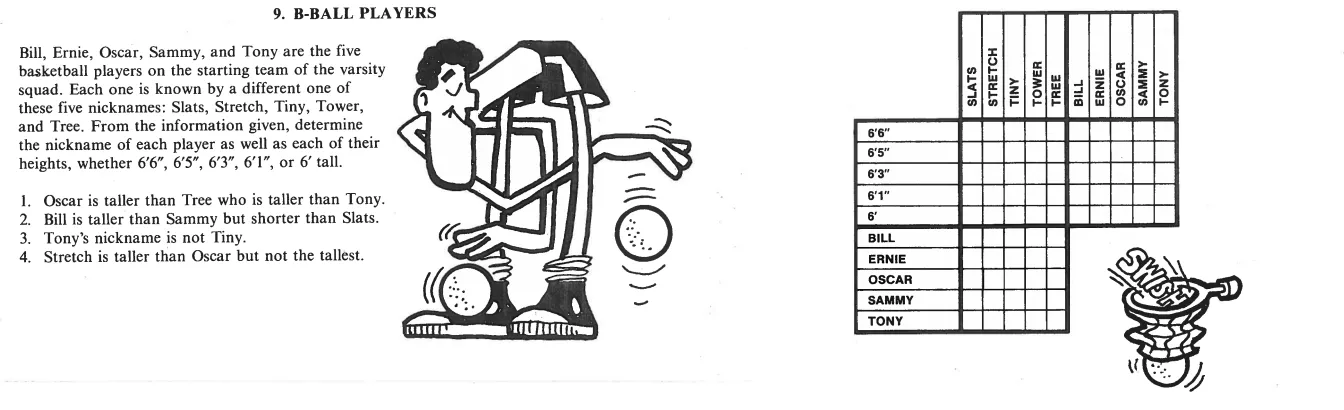
我想知道这些问题是否可以使用编程语言(如R)通过暴力破解来解决。
例如,下面的代码列出了每个篮球运动员按身高可能的所有组合:
my_list = c("Bill", "Ernie", "Oscar", "Sammy", "Tony")
d = permn(my_list)
all_combinations = as.data.frame(matrix(unlist(d), ncol = 120)) |>
setNames(paste0("col", 1:120))
data_frame_version = data.frame(matrix(unlist(d), ncol = length(d))
matrix_version = matrix(unlist(d), ncol = length(d))
#first 20 rows of matrix version:
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14] [,15] [,16] [,17] [,18] [,19]
[1,] "Bill" "Bill" "Bill" "Bill" "Tony" "Tony" "Bill" "Bill" "Bill" "Bill" "Bill" "Bill" "Bill" "Bill" "Tony" "Tony" "Sammy" "Sammy" "Sammy"
[2,] "Ernie" "Ernie" "Ernie" "Tony" "Bill" "Bill" "Tony" "Ernie" "Ernie" "Ernie" "Sammy" "Sammy" "Sammy" "Tony" "Bill" "Sammy" "Tony" "Bill" "Bill"
[3,] "Oscar" "Oscar" "Tony" "Ernie" "Ernie" "Ernie" "Ernie" "Tony" "Sammy" "Sammy" "Ernie" "Ernie" "Tony" "Sammy" "Sammy" "Bill" "Bill" "Tony" "Ernie"
[4,] "Sammy" "Tony" "Oscar" "Oscar" "Oscar" "Sammy" "Sammy" "Sammy" "Tony" "Oscar" "Oscar" "Tony" "Ernie" "Ernie" "Ernie" "Ernie" "Ernie" "Ernie" "Tony"
[5,] "Tony" "Sammy" "Sammy" "Sammy" "Sammy" "Oscar" "Oscar" "Oscar" "Oscar" "Tony" "Tony" "Oscar" "Oscar" "Oscar" "Oscar" "Oscar" "Oscar" "Oscar" "Oscar"
以下代码记录了每个名字和昵称的所有可能组合:
list.a <- as.list(c("Bill", "Ernie", "Oscar", "Sammy", "Tony"))
list.b <- as.list(c("Slats", "Stretch", "Tiny", "Tower", "Tree"))
result.df <- expand.grid(list.a, list.b)
result.list <- lapply(apply(result.df, 1, identity), unlist)
result.list <- result.list[order(sapply(result.list, head, 1))]
head(result.list)
[[1]]
Var1 Var2
"Bill" "Slats"
[[2]]
Var1 Var2
"Bill" "Stretch"
[[3]]
Var1 Var2
"Bill" "Tiny"
[[4]]
Var1 Var2
"Bill" "Tower"
[[5]]
Var1 Var2
"Bill" "Tree"
[[6]]
Var1 Var2
"Ernie" "Slats"
我认为,这两个对象(“matrix_version”和“result.list”)应该包含这个逻辑谜题的正确答案 - 我只是不知道如何从这两个对象中提取正确的组合,以便符合逻辑条件。
请问有人可以向我展示如何做到这一点吗?
谢谢!