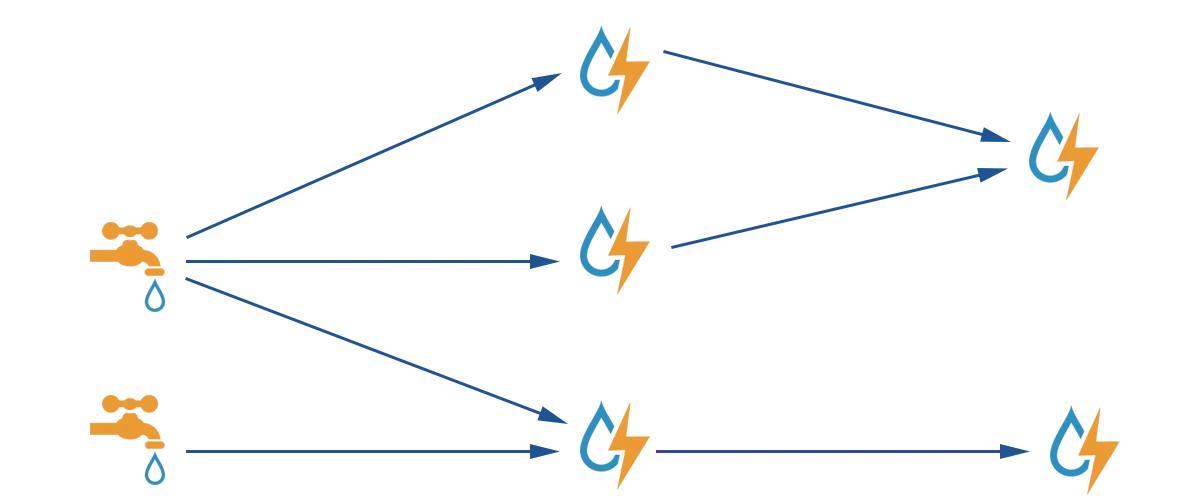
我有一类计算需要使用图形结构来描述。这个图形结构非常复杂,有多个输入、分叉节点和需要其他多个节点结果的节点。在所有计算中,还可能存在多个汇点。但是,这个图不会出现任何环路。输入节点会被更新,值会通过(目前纯粹概念性的)图进行传递。节点保留状态,随着输入的变化而变化,计算必须按照输入的顺序进行。
由于经常需要编写这种计算,我不想每次都写临时代码,因此我尝试编写一个小型库,通过为各个顶点编写类来轻松组合这些计算。但是,我的代码相当不优雅,也没有利用这些计算的并行结构。虽然每个顶点通常都很轻巧,但计算可以变得相当复杂和“宽”。更加复杂的是,这些计算的输入在循环中非常频繁地更新。幸运的是,这些问题规模很小,我可以在单个节点上处理它们。
是否有人遇到过类似的情况?您会推荐哪些思路/方法/工具?