我很好奇,为什么排序算法中的稳定性如此重要或不重要?
10个回答
551
如果一个排序算法可以满足如下条件,即排序后相同关键字的两个对象的顺序与它们在输入数组中出现的顺序相同,则称该算法是稳定的。像插入排序、归并排序、冒泡排序等一些排序算法天生就是稳定的。而像堆排序、快速排序等一些排序算法则不是。
背景信息:一个“稳定的”排序算法能够保持具有相同排序关键字的元素原来的顺序。假设我们有一个由五个字母单词组成的列表:
peach
straw
apple
spork
如果我们只根据每个单词的首字母对列表进行排序,那么稳定排序将产生:
apple
peach
straw
spork
straw 或 spork 的位置,但在稳定的算法中,它们保持相对位置不变(也就是说,由于 straw 在输入中出现在 spork 之前,它在输出中也会出现在 spork 之前)。我们可以使用这个算法来对单词列表进行排序:先按列5、4、3、2、1进行稳定排序。最终,它将被正确排序。请自行确信。(顺便说一下,这个算法叫做基数排序)
现在回答你的问题,假设我们有一个名字列表。我们被要求“按姓氏排序,然后按名字排序”。我们可以先(稳定或不稳定地)按名字排序,然后再按姓氏进行稳定排序。经过这些排序后,列表主要按姓氏排序。但是,在姓氏相同的情况下,名字也会被排序。
你不能以同样的方式堆叠不稳定排序。
- Joey Adams
13
10我们只按照首字母排序。在这种情况下,“straw”和“spork”是相等的。稳定排序将保留原始输入的顺序,而不稳定排序不能保证这一点。“正确”的定义取决于具体应用场景。大多数编程语言中的排序函数允许用户提供一个自定义排序函数。如果用户的函数将不同的项视为相等(例如,相同的名字,不同的姓氏),那么知道原始顺序是否被保留是有帮助的。请参见OCaml的数组排序函数,这是一个真实世界的例子。 - Joey Adams
4我不明白“同样的排序键”这一行是什么意思?这里的“键”是什么意思?请解释一下“同样的排序键”这个语句。 - saplingPro
6@saplingPro:所谓“排序键”,指的是您用来对项目进行排序的内容。因此,当按首字母排序时,每个项目的“排序键”就是它的首字母。 - Joey Adams
1@JoeyAdams 能否请您将您在评论中提供的信息添加到您的答案中。如果您只按照第一个字母排序,那么“spork”确实会排在“straw”之前。否则,我本来要对此进行投票反对。对我来说,这不是一种自然的字符串排序方式,应该明确说明。 - NathanOliver
26比如说你有一个列表,上面记录了每个航班的目的地和出发时间。你要先按照出发时间对列表进行排序,然后再按照目的地排序。如果第二次排序是__稳定的__,那么所有飞往同一目的地的航班就会按照出发时间递增的顺序排在一起。如果第二次排序不稳定,它们就不会按照时间递增的顺序排列。 - roottraveller
显示剩余8条评论
98
稳定的排序算法是指按照输入中出现的顺序对相同元素进行排序,而不稳定的排序则可能无法满足这种情况。- 我感谢我的算法讲师Didem Gozupek提供了有关算法的见解。。
由于一些反馈意见表示有些人不理解演示的逻辑,因此我又需要编辑问题。 它说明了按第一个元素排序。 另一方面,您也可以将演示视为键值对组成的。
稳定的排序算法:
- 插入排序
- 归并排序
- 冒泡排序
- Tim排序
- 计数排序
- 块排序
- Quadsort
- 库排序
- 鸡尾酒搅拌器排序
- 侏儒排序
- 奇偶排序
不稳定的排序算法:
- 堆排序
- 选择排序
- 希尔排序
- 快速排序
- 内省排序(基于快速排序)
- 树排序
- 循环排序
- 平滑排序
- 锦标赛排序(基于堆排序)
- Soner from The Ottoman Empire
5
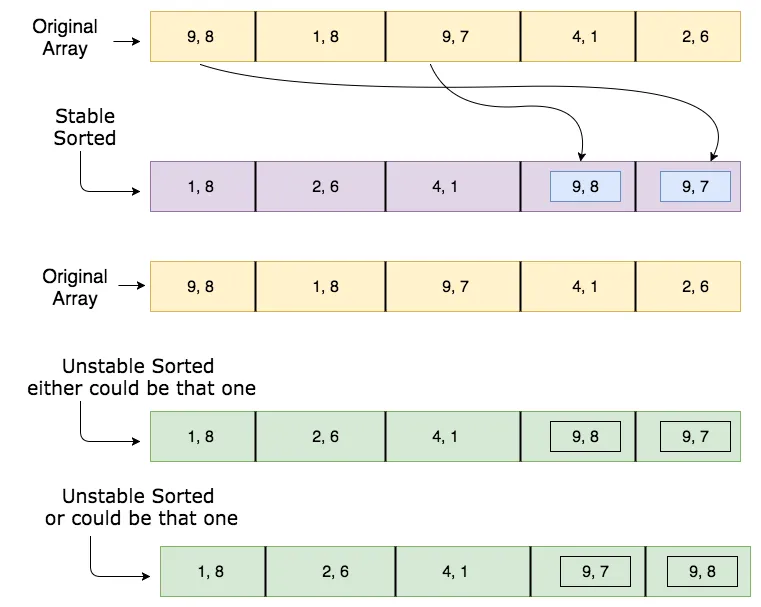
3你的价值观并不相等。你比较了9.7和9.8,但根据稳定性检查,你需要像两个9.7或两个9.8这样的相同值。然后,在稳定算法中,相同的值应该以相同的顺序排序。 - erhun
1不,为了检查稳定性,您的值应该是相同的。我的意思是假设您使用两个9.7并将其命名为节点A和节点B。如果每个排序操作顺序都像A,B(而不是它们相等),则可以理解排序算法是稳定的(例如归并排序)。如果在多次排序时更改A,B的顺序(1.先对A,B进行排序,然后再对B,A进行排序,再对A,B进行排序等),则可以理解排序算法是不稳定的(例如快速排序)@snr - erhun
@snr [9, 6] 在输入数组中不存在。我认为你在最后一个数组条带中想表达的是 [9, 8]。 - Usman
10我相信他只按照逗号前的第一个数字进行排序,并将第二个数字仅用作参考,以便您看到第一个9与第二个9不同。 - Bitcoin Cash - ADA enthusiast
@erhun 什么定义了元素相同?那正是使用的排序准则!它可以是任何人。我的标准是,所有可被10整除的数字都是相等的,无论是20还是500。 - Eduardo Sebastian
32
排序的稳定性意味着具有相同键的记录在排序前后保留它们的相对顺序。
因此,只有当解决的问题需要保留相对顺序时,稳定性才很重要。
如果不需要稳定性,可以使用库中的快速、内存占用少的算法,如堆排序或快速排序,并忘记它。
如果需要稳定性,则更加复杂。稳定算法比不稳定算法具有更高的大O CPU和/或内存使用率。因此,当您有一个大数据集时,必须在CPU和内存之间进行选择。如果CPU和内存都受限制,则会出现问题。一个很好的折衷稳定算法是二叉树排序; Wikipedia文章基于STL提供了一个非常简单的C++实现。
您可以通过将原始记录号添加为每个记录的最后一个键来将不稳定的算法变成稳定的算法。
- Bob Murphy
5
1稳定的算法,如归并排序与快速排序具有相同的O(NlogN)复杂度;但是,它们的时间常数因子更大。 - Jonathan Leffler
1是的,归并排序的内存使用率为O(N),而快速排序的内存使用率为O(log N)。我提到快速排序的原因是qsort()是C标准库例程,因此它很容易获得。 - Bob Murphy
1在我看来,最佳答案是综合性的。其他人提到的多键技术很有趣,但被高估了;它很容易应用,但往往比明显的替代方案慢得多(只需使用一个带有多键比较的排序;或按第一个键排序,然后识别和排序任何具有重复项的子列表)。稳定排序产生可预测的结果在某些应用程序中可能很重要。特别是如果您有两个输入列表A、B,除了列表B有一个额外的条目之外与列表A相同,则稳定排序的输出将是相同的,除了B具有相同的额外条目。最后一段加1。 - greggo
在最后一句话中,我不明白你所说的“每个记录的最后一个键”的意思 - 你能解释一下吗?总体来说,非常好的信息性评论 :) - augenss
2如果两条记录都具有键“foo”,则在进行排序之前将它们更改为类似于“foo_00001”和“foo_00002”的内容。这将在进行排序时保留两个键的原始顺序。然后,在完成排序后,将两个键都更改回“foo”。 - Bob Murphy
26
这取决于你的操作。
假设你有一些人员记录,其中包含名字和姓氏字段。首先按照名字字段对列表进行排序,然后使用稳定的算法按照姓氏字段再次排序,这样你就得到了一个既按名字排序又按姓氏排序的列表。
- svens
17
稳定性的重要性有几个方面。其中之一是,如果两条记录不需要被交换,那么通过交换它们,可能会导致内存更新,页面被标记为脏页,并且需要重新写入磁盘(或其他慢速媒介)。
- Clinton Pierce
2
记录交换与稳定性有什么关系? - user1683793
如果您保留顺序,则对于某些输入,它可能具有更少的元素“转移”,这将导致额外的内存页面写入... FWIW。 - rogerdpack
4
如果两个具有相等键的对象在排序输出中以与它们在未排序数组中出现的顺序相同的顺序出现,则称排序算法为稳定的。一些排序算法天生就是稳定的,如插入排序、归并排序、冒泡排序等。而一些排序算法则不是,如堆排序、快速排序等。
然而,任何不稳定的给定排序算法都可以被修改为稳定的。可能会有特定于排序算法的方法来使其稳定,但通常,任何基于比较的排序算法都可以通过改变键比较操作来使其稳定,以便对于具有相等键的对象,比较两个键时将位置视为一个因素。
然而,任何不稳定的给定排序算法都可以被修改为稳定的。可能会有特定于排序算法的方法来使其稳定,但通常,任何基于比较的排序算法都可以通过改变键比较操作来使其稳定,以便对于具有相等键的对象,比较两个键时将位置视为一个因素。
References: http://www.math.uic.edu/~leon/cs-mcs401-s08/handouts/stability.pdf http://en.wikipedia.org/wiki/Sorting_algorithm#Stability
- roottraveller
4
- John R Perry
2
一些需要使用稳定排序的例子是数据库。以交易数据库为例,其中包括姓氏|名字、购买日期|时间、项目编号、价格。假设该数据库通常按照日期|时间排序。然后进行查询,通过姓氏|名字对数据库进行排序,由于稳定排序保留了原始顺序,即使查询只涉及姓氏|名字,每个姓氏|名字的交易也将按照日期|时间顺序排列。
另一个类似的例子是经典的Excel,它将排序限制在3列之内。要对6列进行排序,首先使用最不重要的3列进行排序,然后使用最重要的3列进行排序。
稳定基数排序的一个经典例子是卡片分类器,用于按10进制数字列的字段进行排序。卡片按从最低有效数字到最高有效数字的顺序排序。在每个传递中,读取一副卡牌,并根据该列中的数字将其分成10个不同的箱子。然后将10个箱子的卡片按顺序放回输入漏斗中(“0”卡片首先,“9”卡片最后)。然后进行下一列的传递,直到所有列都排序完毕。实际的卡片分类器具有超过10个箱子,因为卡片上有12个区域,某些列可能为空,而且有一个误读箱。要对字母进行排序,需要每列进行2次传递,第一次传递是数字,第二次传递是12 11区。
后来(1937年),出现了可以通过比较字段合并两副卡牌的卡片整理(合并)机器。输入是两副已经排序好的卡牌,即主卡组和更新卡组。整理机将两个卡组合并成一个新的主箱和一个存档箱,如果有重复,则可选择将其用于主卡组的副本,以便新的主箱中只包含更新卡。这可能是最初(自下而上)归并排序背后的想法基础。
另一个类似的例子是经典的Excel,它将排序限制在3列之内。要对6列进行排序,首先使用最不重要的3列进行排序,然后使用最重要的3列进行排序。
稳定基数排序的一个经典例子是卡片分类器,用于按10进制数字列的字段进行排序。卡片按从最低有效数字到最高有效数字的顺序排序。在每个传递中,读取一副卡牌,并根据该列中的数字将其分成10个不同的箱子。然后将10个箱子的卡片按顺序放回输入漏斗中(“0”卡片首先,“9”卡片最后)。然后进行下一列的传递,直到所有列都排序完毕。实际的卡片分类器具有超过10个箱子,因为卡片上有12个区域,某些列可能为空,而且有一个误读箱。要对字母进行排序,需要每列进行2次传递,第一次传递是数字,第二次传递是12 11区。
后来(1937年),出现了可以通过比较字段合并两副卡牌的卡片整理(合并)机器。输入是两副已经排序好的卡牌,即主卡组和更新卡组。整理机将两个卡组合并成一个新的主箱和一个存档箱,如果有重复,则可选择将其用于主卡组的副本,以便新的主箱中只包含更新卡。这可能是最初(自下而上)归并排序背后的想法基础。
- rcgldr
1
如果你假设你要排序的只是数字,它们的值才能识别/区分它们(例如具有相同值的元素是相同的),那么排序的稳定性问题就没有意义。
然而,在排序中具有相同优先级的对象可能是不同的,有时它们的相对顺序是有意义的信息。在这种情况下,不稳定的排序会产生问题。
例如,您有一个数据列表,其中包含所有玩家在游戏中清理迷宫的时间成本[T]和难度等级[L]。假设我们需要按照他们清理迷宫的速度对玩家进行排名。然而,另一个规则适用:清理更高难度迷宫的玩家总是比清理时间长的玩家排名更高。
当然,您可以尝试使用某些算法将配对值[T,L]映射到实数[R],并根据[R]值对所有玩家进行排名。
但是,如果稳定排序是可行的,那么您可以简单地按[T](更快的玩家优先)对整个列表进行排序,然后按[L]排序。在这种情况下,玩家(按时间成本)的相对顺序在按他们清理的迷宫难度级别分组后不会改变。
然而,在排序中具有相同优先级的对象可能是不同的,有时它们的相对顺序是有意义的信息。在这种情况下,不稳定的排序会产生问题。
例如,您有一个数据列表,其中包含所有玩家在游戏中清理迷宫的时间成本[T]和难度等级[L]。假设我们需要按照他们清理迷宫的速度对玩家进行排名。然而,另一个规则适用:清理更高难度迷宫的玩家总是比清理时间长的玩家排名更高。
当然,您可以尝试使用某些算法将配对值[T,L]映射到实数[R],并根据[R]值对所有玩家进行排名。
但是,如果稳定排序是可行的,那么您可以简单地按[T](更快的玩家优先)对整个列表进行排序,然后按[L]排序。在这种情况下,玩家(按时间成本)的相对顺序在按他们清理的迷宫难度级别分组后不会改变。
PS: 当然,两次排序的方法并不是解决这个特定问题的最佳方案,但为了解释海报的问题,它应该足够了。
- M Ciel
0
稳定排序将始终在相同的输入上返回相同的解决方案(排列)。
例如,[2,1,2]将使用稳定排序作为排列[2,1,3]进行排序(首先是索引2,然后是索引1,然后是索引3在排序输出中)。这意味着输出总是以相同的方式洗牌。其他非稳定但仍然正确的排列是[2,3,1]。
快速排序不是稳定排序,同一元素之间的排列差异取决于选择枢轴的算法。一些实现是随机选择的,这可能会使快速排序在使用相同算法的相同输入时产生不同的排列。
稳定排序算法是必要的确定性。
- Luka Rahne
5
2这不是稳定性的意思。请参见http://en.wikipedia.org/wiki/Sorting_algorithm#Stability。 - Luís Oliveira
我应该更正最后一句话,即非稳定排序甚至可以在相同的实现中输出不同的解决方案,而任何稳定排序都会输出相同的解决方案。 - Luka Rahne
1为什么是-1?有人可以指出这里错在哪里吗?这不是稳定排序的含义,而是稳定排序的属性。 - Luka Rahne
排序算法是否确定性并不决定其是否稳定。我可以通过定义不同的打破平局行为(例如通过对非关键部分进行子排序)来编写一个非稳定的确定性排序算法。稳定排序特别指当平局被排序时,预排序的元素相对顺序得以保留。稳定排序的输出示例:
sort([(5,3),(1,5),(3,3),(1,3)], x) => [(1,5),(1,3),(3,3),(5,3)]。我可以制作一个始终(确定性地)输出[(1,3),(1,5),(3,3),(5,3)]的确定性排序,但这不是一种稳定排序。 - cowbert@cowbert 这是一个关于每个稳定排序都具有的好特性的陈述。也就是说,无论使用哪种稳定排序算法或实现,每次结果都将相同。在不同的非稳定排序实现中维护这样的属性更加困难。 - Luka Rahne
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
IBM(插入排序,冒泡排序,归并排序)- roottraveller