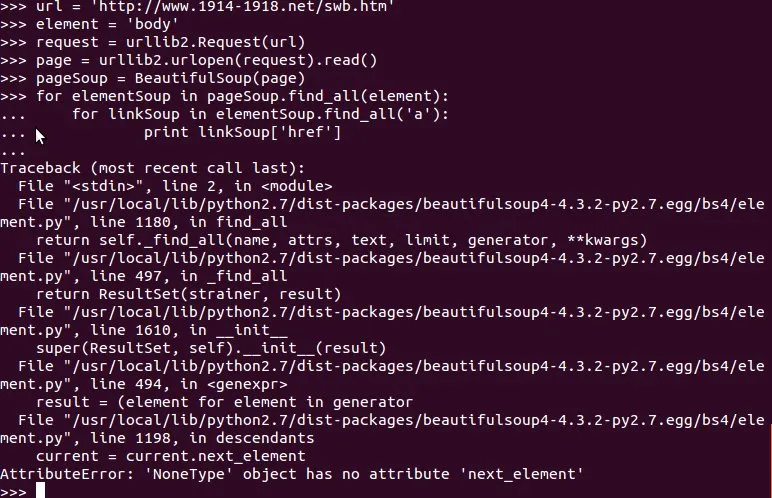
我正在使用Beautiful Soup来获取网页正文中的超链接。以下是我使用的代码:
import urllib2
from bs4 import BeautifulSoup
url = 'http://www.1914-1918.net/swb.htm'
element = 'body'
request = urllib2.Request(url)
page = urllib2.urlopen(request).read()
pageSoup = BeautifulSoup(page)
for elementSoup in pageSoup.find_all(element):
for linkSoup in elementSoup.find_all('a'):
print linkSoup['href']
我在尝试查找swb.htm页面的超链接时遇到了AttributeError错误。
AttributeError: 'NoneType'对象没有'next_element'属性
我确定在body元素下有一个或几个'a'元素。但是奇怪的是,它在其他页面(例如http://www.1914-1918.net/1div.htm)中运行良好。
这个问题困扰我已经几天了。请问有人能指出我做错了什么吗?
截图