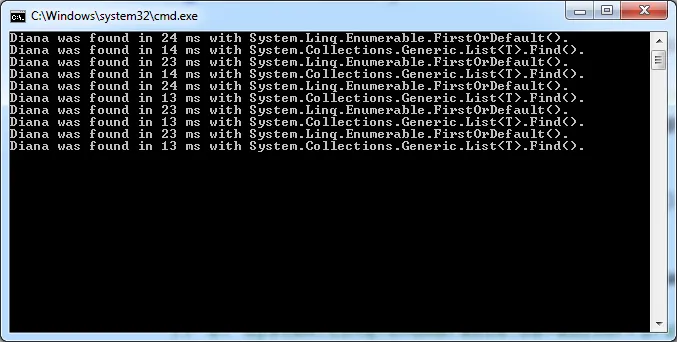
在一个简单的引用类型的大序列中搜索Diana时,得到了一个有趣的结果,该引用类型只有一个字符串属性。
Find()的运行速度几乎是两倍快,希望.Net团队将来不会将其标记为过时。
using System;
using System.Collections.Generic;
using System.Linq;
public class Customer{
public string Name {get;set;}
}
Stopwatch watch = new Stopwatch();
const string diana = "Diana";
while (Console.ReadKey().Key != ConsoleKey.Escape)
{
//Armour with 1000k++ customers. Wow, should be a product with a great success! :)
var customers = (from i in Enumerable.Range(0, 1000000)
select new Customer
{
Name = Guid.NewGuid().ToString()
}).ToList();
customers.Insert(999000, new Customer { Name = diana }); // Putting Diana at the end :)
//1. System.Linq.Enumerable.DefaultOrFirst()
watch.Restart();
customers.FirstOrDefault(c => c.Name == diana);
watch.Stop();
Console.WriteLine("Diana was found in {0} ms with System.Linq.Enumerable.FirstOrDefault().", watch.ElapsedMilliseconds);
//2. System.Collections.Generic.List<T>.Find()
watch.Restart();
customers.Find(c => c.Name == diana);
watch.Stop();
Console.WriteLine("Diana was found in {0} ms with System.Collections.Generic.List<T>.Find().", watch.ElapsedMilliseconds);
}
Find()的运行速度几乎是两倍快,希望.Net团队将来不会将其标记为过时。
 .
.
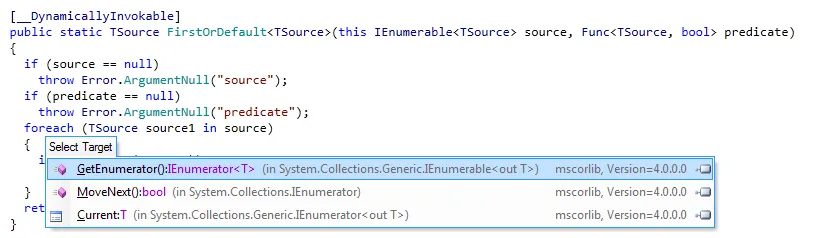
FirstOrDefault之前对Find()计时。那么结果是什么? - OdedFirstOrDefault每个项需要三次间接调用,而Find只需要一次间接调用。 - CodesInChaos