我了解一些计算凸包的算法。其中大多数算法的时间复杂度为 O(n*log(n)),其中 n 是输入点的数量。
设 S = {p_1, p_2, ..., p_n} 为一组按照 x 坐标排序的点集,即 p_1.x <= p_2.x <= ... <= p_n.x。
我需要描述一个算法来在 O(n) 时间内计算出 S 的凸包 CH(S)。此外,我还需要分析该算法的运行时间。
我了解一些计算凸包的算法。其中大多数算法的时间复杂度为 O(n*log(n)),其中 n 是输入点的数量。
设 S = {p_1, p_2, ..., p_n} 为一组按照 x 坐标排序的点集,即 p_1.x <= p_2.x <= ... <= p_n.x。
我需要描述一个算法来在 O(n) 时间内计算出 S 的凸包 CH(S)。此外,我还需要分析该算法的运行时间。
排序点的时间复杂度为O(n log n)。虽然循环的时间复杂度似乎是O(n^2),因为对于每个点,它都会回到前面检查是否有任何先前的点组成“右转”,但实际上它是O(n),因为每个点在某种意义上最多被考虑两次。[...] 因此,总时间复杂度为O(n log n),因为排序的时间支配了实际计算凸包的时间。
因此,在您的情况下,您可以跳过排序部分,从而使时间复杂度达到O(n)。
实际上,文章在注释中继续:
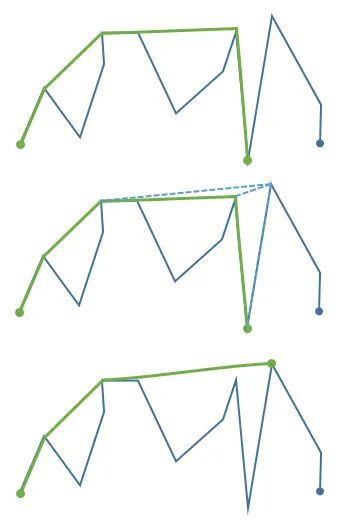
相同的基本思路也适用于输入按x坐标排序而不是角度,并且分两步计算凸包,分别产生凸包的上部和下部。[...]我无法抵制解释这个过程。
点按字典顺序(x,y)排序。
假设我们已经构建了前K个点的上凸壳。如果我们想要得到前K+1个点的上凸壳,我们必须找到新点和上凸壳之间的“桥梁”。这是通过在凸壳上回溯来完成的,直到新点和凸壳的一条边形成凸角。
当我们回溯时,丢弃形成凹角的边,在最后将新点链接到自由端点。(在图中,我们尝试三条边并且丢弃其中两条。)现在我们有了前K+1个点的上凸壳。