我最近遇到了一个问题。
我需要在页面上找到一个包含特定文本的div标签。问题是,这个文本被内部链接标签分成两部分,因此HTML树看起来像:
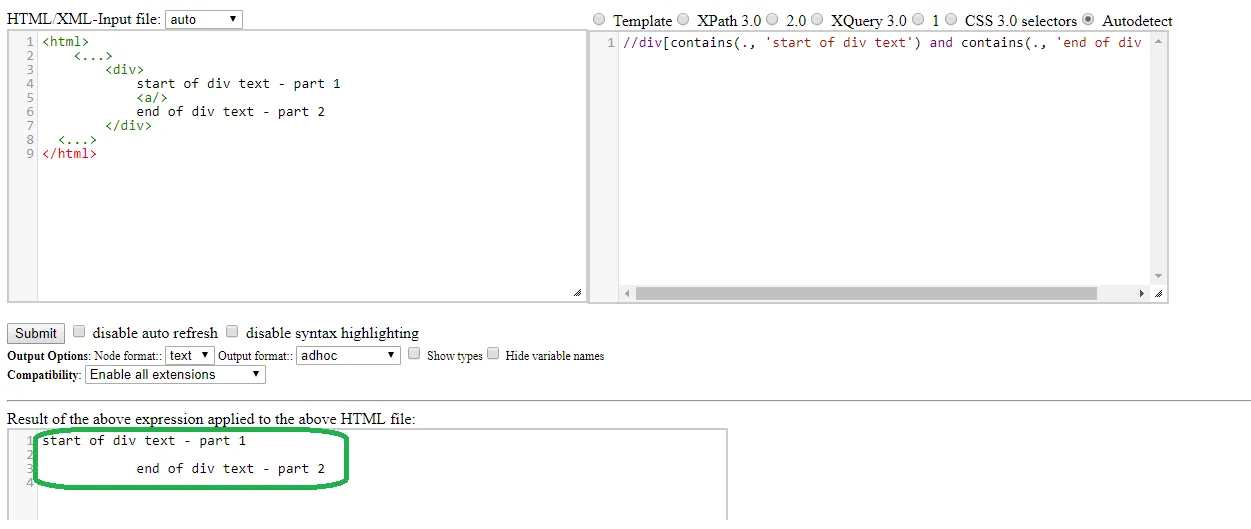
**<html>
<...>
<div>
start of div text - part 1
<a/>
end of div text - part 2
</div>
<...>
</html>**
为了唯一地标识那个div标签,我需要div文本的两个部分。自然而然,我会想出这样的XPath:
.//div[contains(text(), 'start of div text') and contains(text(), 'end of div text')]
然而,它并不起作用,第二部分找不到。
如何最好地描述这种标签的唯一性?