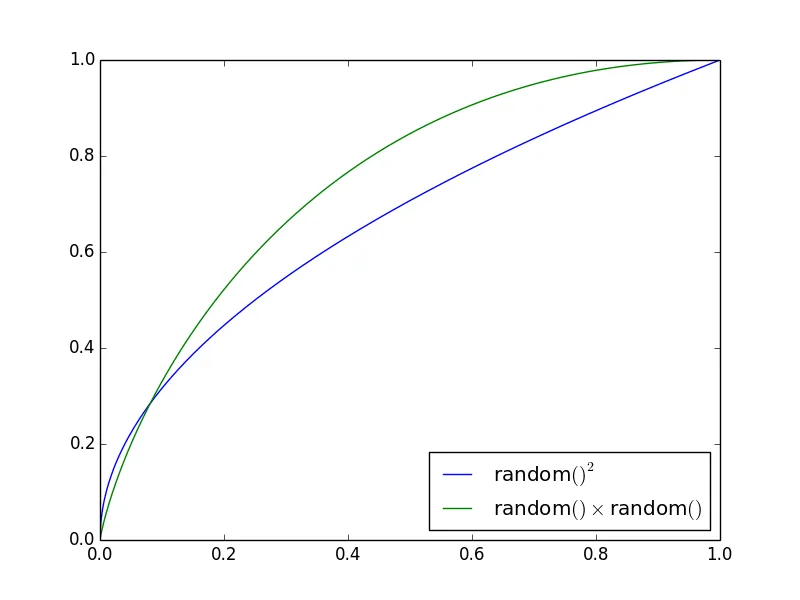
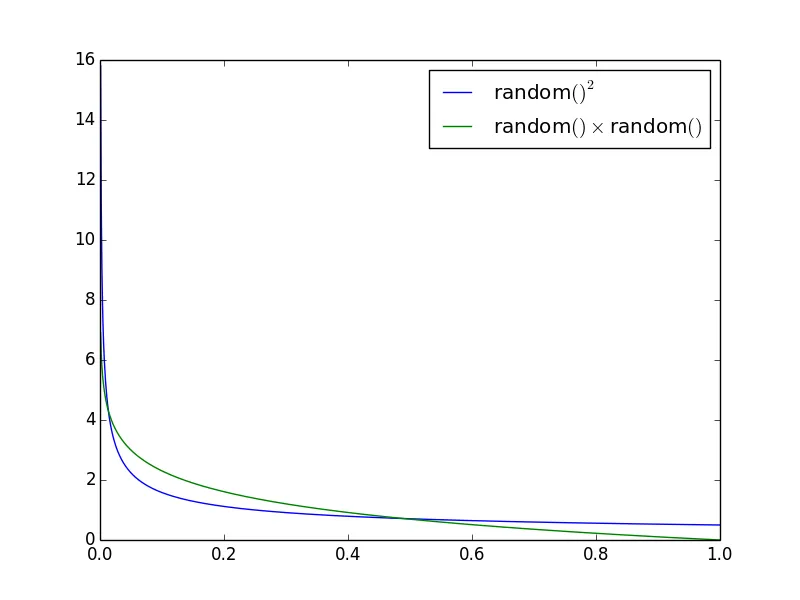
random() * random()和random() ** 2之间有区别吗?random()返回一个从均匀分布中在0到1之间的值。当测试这两个版本的随机平方数时,我注意到了一点差异。我创建了100,000个随机平方数,并计算了每个0.01间隔(从0.00到0.01,0.01到0.02等)中有多少个数字。似乎这些版本的平方随机数生成是不同的。
将一个随机数平方而不是将两个随机数相乘,使您重复使用一个随机数,但我认为分布应该保持不变。真的有区别吗?如果没有,为什么我的测试显示了差异?
我生成了两个随机分布,一个是
random() * random(),另一个是random() ** 2:from random import random
lst = [0 for i in range(100)]
lst2, lst3 = list(lst), list(lst)
#create two random distributions for random() * random()
for i in range(100000):
lst[int(100 * random() * random())] += 1
for i in range(100000):
lst2[int(100 * random() * random())] += 1
for i in range(100000):
lst3[int(100 * random() ** 2)] += 1
这提供了
>>> lst
[
5626, 4139, 3705, 3348, 3085, 2933, 2725, 2539, 2449, 2413,
2259, 2179, 2116, 2062, 1961, 1827, 1754, 1743, 1719, 1753,
1522, 1543, 1513, 1361, 1372, 1290, 1336, 1274, 1219, 1178,
1139, 1147, 1109, 1163, 1060, 1022, 1007, 952, 984, 957,
906, 900, 843, 883, 802, 801, 710, 752, 705, 729,
654, 668, 628, 633, 615, 600, 566, 551, 532, 541,
511, 493, 465, 503, 450, 394, 405, 405, 404, 332,
369, 369, 332, 316, 272, 284, 315, 257, 224, 230,
221, 175, 209, 188, 162, 156, 159, 114, 131, 124,
96, 94, 80, 73, 54, 45, 43, 23, 18, 3
]
>>> lst2
[
5548, 4218, 3604, 3237, 3082, 2921, 2872, 2570, 2479, 2392,
2296, 2205, 2113, 1990, 1901, 1814, 1801, 1714, 1660, 1591,
1631, 1523, 1491, 1505, 1385, 1329, 1275, 1308, 1324, 1207,
1209, 1208, 1117, 1136, 1015, 1080, 1001, 993, 958, 948,
903, 843, 843, 849, 801, 799, 748, 729, 705, 660,
701, 689, 676, 656, 632, 581, 564, 537, 517, 525,
483, 478, 473, 494, 457, 422, 412, 390, 384, 352,
350, 323, 322, 308, 304, 275, 272, 256, 246, 265,
227, 204, 171, 191, 191, 136, 145, 136, 108, 117,
93, 83, 74, 77, 55, 38, 32, 25, 21, 1
]
>>> lst3
[
10047, 4198, 3214, 2696, 2369, 2117, 2010, 1869, 1752, 1653,
1552, 1416, 1405, 1377, 1328, 1293, 1252, 1245, 1121, 1146,
1047, 1051, 1123, 1100, 951, 948, 967, 933, 939, 925,
940, 893, 929, 874, 824, 843, 868, 800, 844, 822,
746, 733, 808, 734, 740, 682, 713, 681, 675, 686,
689, 730, 707, 677, 645, 661, 645, 651, 649, 672,
679, 593, 585, 622, 611, 636, 543, 571, 594, 593,
629, 624, 593, 567, 584, 585, 610, 549, 553, 574,
547, 583, 582, 553, 536, 512, 498, 562, 536, 523,
553, 485, 503, 502, 518, 554, 485, 482, 470, 516
]
预期的随机误差是前两个之间的差异:
[
78, 79, 101, 111, 3, 12, 147, 31, 30, 21,
37, 26, 3, 72, 60, 13, 47, 29, 59, 162,
109, 20, 22, 144, 13, 39, 61, 34, 105, 29,
70, 61, 8, 27, 45, 58, 6, 41, 26, 9,
3, 57, 0, 34, 1, 2, 38, 23, 0, 69,
47, 21, 48, 23, 17, 19, 2, 14, 15, 16,
28, 15, 8, 9, 7, 28, 7, 15, 20, 20,
19, 46, 10, 8, 32, 9, 43, 1, 22, 35,
6, 29, 38, 3, 29, 20, 14, 22, 23, 7,
3, 11, 6, 4, 1, 7, 11, 2, 3, 2
]
但第一组和第三组之间的差异要大得多,这表明它们的分布不同:
[
4421, 59, 491, 652, 716, 816, 715, 670, 697, 760,
707, 763, 711, 685, 633, 534, 502, 498, 598, 607,
475, 492, 390, 261, 421, 342, 369, 341, 280, 253,
199, 254, 180, 289, 236, 179, 139, 152, 140, 135,
160, 167, 35, 149, 62, 119, 3, 71, 30, 43,
35, 62, 79, 44, 30, 61, 79, 100, 117, 131,
168, 100, 120, 119, 161, 242, 138, 166, 190, 261,
260, 255, 261, 251, 312, 301, 295, 292, 329, 344,
326, 408, 373, 365, 374, 356, 339, 448, 405, 399,
457, 391, 423, 429, 464, 509, 442, 459, 452, 513
]




random()两次,你会得到2个不同的数字。而random()^2是平方运算 - 我没有看到混淆之处。 - karthikrrandom()以相等的概率返回 0.0 或 1.0,那么pow(random(), 2)将以相等的概率返回 0.0 或 1.0。但是random() * random()返回 0.0 的可能性为 75%,1.0 的可能性为 25%。即使在这种非常简单的情况下,分布也非常不同。现在重新进行分析,假设random()均匀随机地返回 0.0、0.5 或 1.0。以此类推,重复这个过程直到彻底理解。;-) - Tim Peters