这里有一些好的帖子(例如这个),介绍如何在MATLAB中制作循环缓冲区。但是从它们的内容来看,我不认为它们适合我的应用,因为我正在寻找的是在MATLAB中实现的循环缓冲解决方案,而不涉及任何旧数据的复制。
举个简单的例子,假设我每次处理50个样本,并且每次读入10个样本。我将首先运行5次迭代,填充我的缓冲区,在最后处理我的50个样本。所以我的缓冲区将会是:
问题在于 - 我不想每次都复制旧数据 B2、B3、B4、B5,因为这样会花费很多时间(我的数据集非常大)。
我想知道是否有一种方法可以在不复制“旧”数据的情况下完成此操作。谢谢。
举个简单的例子,假设我每次处理50个样本,并且每次读入10个样本。我将首先运行5次迭代,填充我的缓冲区,在最后处理我的50个样本。所以我的缓冲区将会是:
[B1 B2 B3 B4 B5]
每个“B”都是由10个样本组成的块。
现在,我读取了接下来的10个样本,称它们为B6。我希望我的缓冲区现在看起来像:
[B2 B3 B4 B5 B6]
问题在于 - 我不想每次都复制旧数据 B2、B3、B4、B5,因为这样会花费很多时间(我的数据集非常大)。
我想知道是否有一种方法可以在不复制“旧”数据的情况下完成此操作。谢谢。
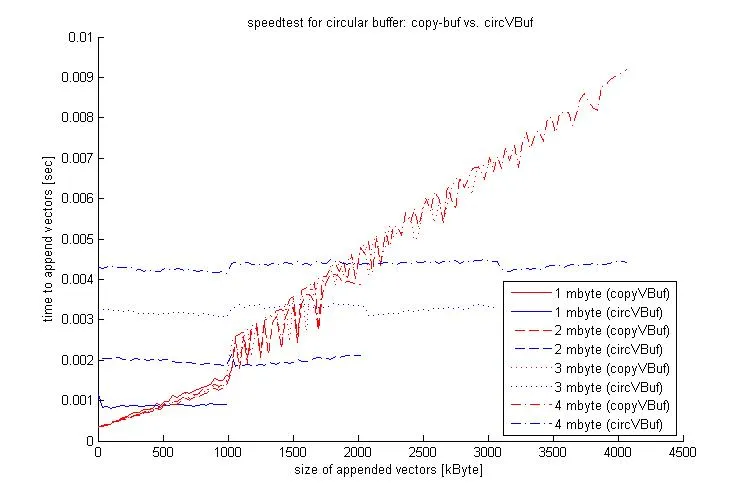
mod命令可能更快且更紧凑。此外,该方法明确使用数组而不是单元数组。这意味着您无需修改现有代码或调用cell2mat或等效操作——这将需要不必要的复制操作。 - Steve