我正在尝试构建一个应用程序来检测网页中的广告图片。一旦我检测到它们,就不会允许它们在客户端显示。
根据这个Stackoverflow问题,我认为SVM是实现我的目标的最佳方法。
因此,我自己编写了SVM和SMO。我从UCI数据存储库获得的数据集有3280个实例(数据集链接),其中约400个来自代表广告图片的类,其余的则代表非广告图片。
现在,我正在使用前2800个输入集来训练SVM。但是,在查看准确率后,我意识到大多数这些输入集来自非广告图像类。因此,我对该类别的准确性非常高。
那么我该怎么办?我应该给SVM多少输入集进行训练,每个类别应该有多少个?
感谢。干杯。(基本上是因为上一个问题的背景不同,所以我创建了一个新问题。神经网络输入数据的优化)
根据这个Stackoverflow问题,我认为SVM是实现我的目标的最佳方法。
因此,我自己编写了SVM和SMO。我从UCI数据存储库获得的数据集有3280个实例(数据集链接),其中约400个来自代表广告图片的类,其余的则代表非广告图片。
现在,我正在使用前2800个输入集来训练SVM。但是,在查看准确率后,我意识到大多数这些输入集来自非广告图像类。因此,我对该类别的准确性非常高。
那么我该怎么办?我应该给SVM多少输入集进行训练,每个类别应该有多少个?
感谢。干杯。(基本上是因为上一个问题的背景不同,所以我创建了一个新问题。神经网络输入数据的优化)
谢谢回复。 我想确认我是否正确地推导出了广告和非广告类别的C值。 请给我反馈。
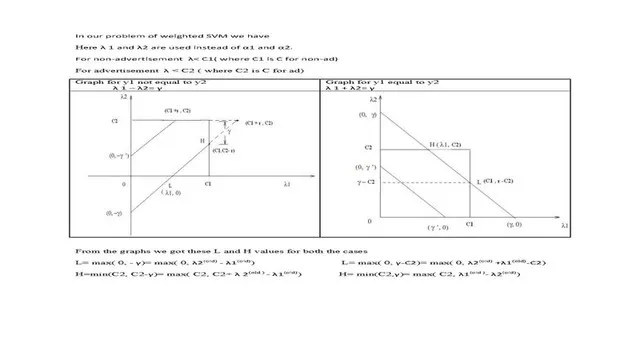
或者您可以在这里查看文档版本。
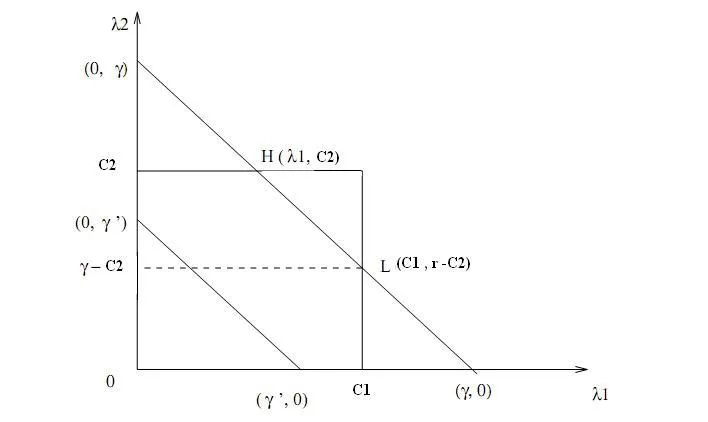
您可以在此处查看y1等于y2的图形
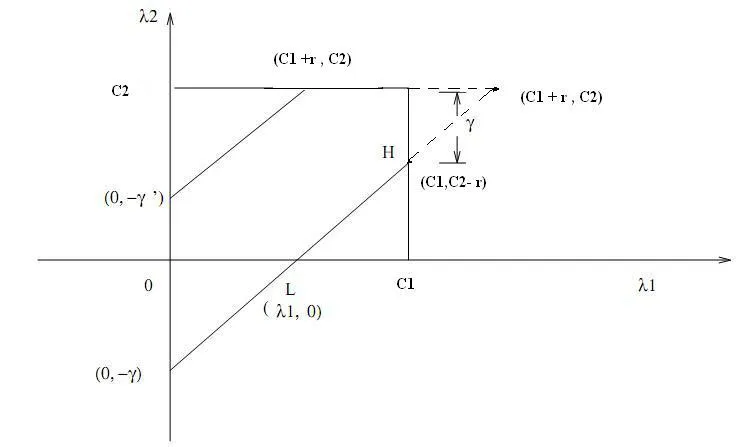
以及y1不等于y2的图形