假设我做了类似这样的事情:
def readDataset: Dataset[Row] = ???
val ds1 = readDataset.cache();
val ds2 = ds1.withColumn("new", lit(1)).cache();
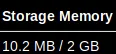
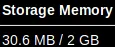
ds2和ds1除了"new"列之外的所有列数据会共享吗?如果我缓存两个数据集,那么整个数据集ds和ds2是否都将保存在内存中,还是只存储共享数据一次?如果数据被共享,那么什么情况下会破坏这种共享(即相同的数据存储在两个内存位置中)?
我知道数据集和rdd是不可变的,但我找不到明确的答案来解释它们是否共享数据。