一个非常简单的示例应用程序(.NET 4.6.2)在递归深度为12737时会产生StackOverflowException,如果最内部的函数调用抛出异常,则递归深度将降至10243,这是预期的并且可以接受的。
如果我使用
注意:只有编译为x64时,才能观察到递归深度为105的StackOverflowException。对于x86(32位),该效果首先发生在深度为4272的位置。Mono(如https://repl.it所使用的)在深度为74200之前都可以正常工作。
StackOverflowException不会在深度递归中发生,而是在返回主例程时发生。 finally块在一些深度上被处理,然后程序死亡:
或者在调试器中:
谁能解释这个?
更新:问题可以在递归方法中使用try-catch-throw块而不使用
如果我使用
Lazy<T>来短暂地保存中间结果,如果没有异常抛出,StackOverflowException已经在递归深度为2207时发生,如果有异常抛出,则在递归深度为105时发生。注意:只有编译为x64时,才能观察到递归深度为105的StackOverflowException。对于x86(32位),该效果首先发生在深度为4272的位置。Mono(如https://repl.it所使用的)在深度为74200之前都可以正常工作。
StackOverflowException不会在深度递归中发生,而是在返回主例程时发生。 finally块在一些深度上被处理,然后程序死亡:
Exception System.InvalidOperationException at 105
Finally at 105
...
Exception System.InvalidOperationException at 55
Finally at 55
Exception System.InvalidOperationException at 54
Finally at 54
Process is terminated due to StackOverflowException.
或者在调试器中:
The program '[xxxxx] Test.vshost.exe' has exited with code -2147023895 (0x800703e9).
谁能解释这个?
public class Program
{
private class Test
{
private int maxDepth;
private int CalculateWithLazy(int depth)
{
try
{
var lazy = new Lazy<int>(() => this.Calculate(depth));
return lazy.Value;
}
catch (Exception e)
{
Console.WriteLine("Exception " + e.GetType() + " at " + depth);
throw;
}
finally
{
Console.WriteLine("Finally at " + depth);
}
}
private int Calculate(int depth)
{
if (depth >= this.maxDepth) throw new InvalidOperationException("Max. recursion depth reached.");
return this.CalculateWithLazy(depth + 1);
}
public void Run()
{
for (int i = 1; i < 100000; i++)
{
this.maxDepth = i;
try
{
Console.WriteLine("MaxDepth: " + i);
this.CalculateWithLazy(0);
}
catch { /* ignore */ }
}
}
}
public static void Main(string[] args)
{
var test = new Test();
test.Run();
Console.Read();
}
更新:问题可以在递归方法中使用try-catch-throw块而不使用
Lazy<T>来重现。 [MethodImpl(MethodImplOptions.NoInlining)]
private int Calculate(int depth)
{
try
{
if (depth >= this.maxDepth) throw new InvalidOperationException("Max. recursion depth reached.");
return this.Calculate2(depth + 1);
}
catch
{
throw;
}
}
[MethodImpl(MethodImplOptions.NoInlining)]
private int Calculate2(int depth) // just to prevent the compiler from tail-recursion-optimization
{
return this.Calculate(depth);
}
public void Run()
{
for (int i = 1; i < 100000; i++)
{
this.maxDepth = i;
try
{
Console.WriteLine("MaxDepth: " + i);
this.Calculate(0);
}
catch(Exception e)
{
Console.WriteLine("Finished with " + e.GetType());
}
}
}
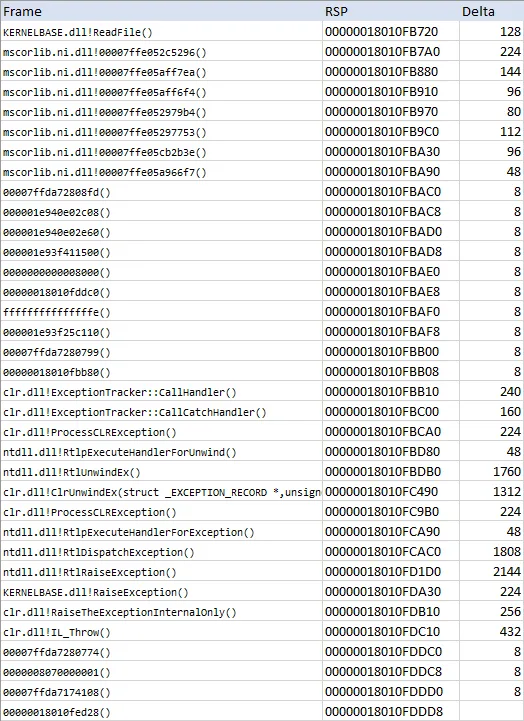
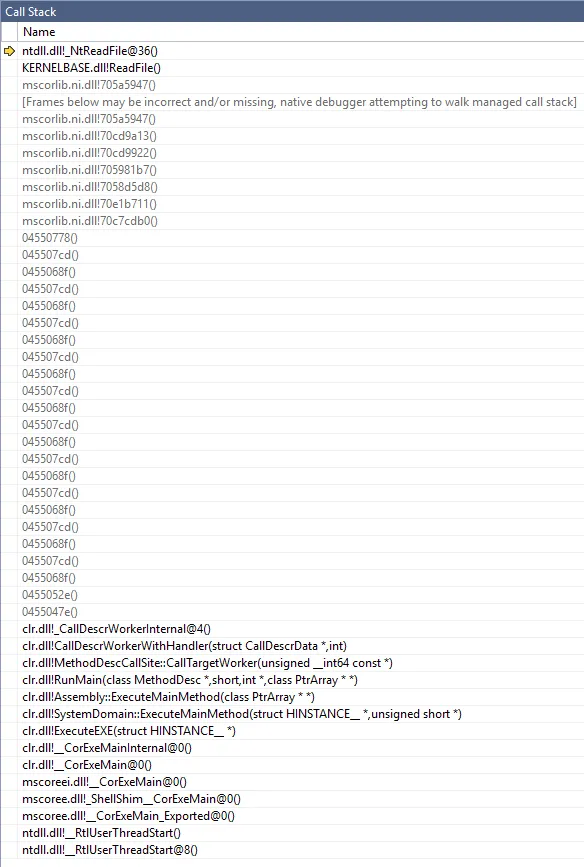
CalculateWithLazy调用Calculate,而Calculate又调用CalculateWithLazy。你有没有注意到这一点?这就是递归发生的无限循环,并导致堆栈溢出异常。 - Chetancatch { throw; }在每一帧都重新抛出了这个异常(由于递归,你的try块被嵌套:try { try { try { ...)。因此,异常被捕获并重新抛出了 <最大递归深度> 次,这显然会消耗相当多的堆栈空间。 - Evk