我在想如何实现像SO上使用的标签系统,我考虑过以下方案,但无法想出一个好的可扩展解决方案。
我考虑采用基本的3个表结构:一个tags表、一个articles表和一个tag_to_articles表。
这是解决此问题的最佳方案吗?还有其他替代方案吗?使用这种方法,随着时间的推移,表格将变得非常大,在搜索方面效率也不太高。另一方面,查询执行速度并不是非常重要。


交集(AND)
查询“search+webservice+semweb”:
SELECT *
FROM `delicious`
WHERE tags LIKE "%search%"
AND tags LIKE "%webservice%"
AND tags LIKE "%semweb%"
联合查询(或者) 针对“search|webservice|semweb”的查询:
SELECT *
FROM `delicious`
WHERE tags LIKE "%search%"
OR tags LIKE "%webservice%"
OR tags LIKE "%semweb%"
针对“search+webservice-semweb”的Minus查询
SELECT *
FROM `delicious`
WHERE tags LIKE "%search%"
AND tags LIKE "%webservice%"
AND tags NOT LIKE "%semweb%"
Scuttle将其数据组织在两个表中。那张名为“scCategories”的表是“标签”表,它有一个指向“书签”表的外键。
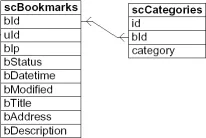
交集查询 (AND) 查询“bookmark+webservice+semweb”:
SELECT b.*
FROM scBookmarks b, scCategories c
WHERE c.bId = b.bId
AND (c.category IN ('bookmark', 'webservice', 'semweb'))
GROUP BY b.bId
HAVING COUNT( b.bId )=3
首先,搜索所有书签标记组合,其中标记为“bookmark”,“webservice”或“semweb”(c.category IN('bookmark','webservice','semweb')),然后仅考虑已搜索到所有三个标记的书签(HAVING COUNT(b.bId)= 3)。
联合(OR) 查询“bookmark | webservice | semweb”: 只需省略HAVING子句即可使用联合:
SELECT b.*
FROM scBookmarks b, scCategories c
WHERE c.bId = b.bId
AND (c.category IN ('bookmark', 'webservice', 'semweb'))
GROUP BY b.bId
减法(排除) 针对“bookmark+webservice-semweb”进行查询,即:书签 AND Web服务 AND NOT 语义Web。
SELECT b. *
FROM scBookmarks b, scCategories c
WHERE b.bId = c.bId
AND (c.category IN ('bookmark', 'webservice'))
AND b.bId NOT
IN (SELECT b.bId FROM scBookmarks b, scCategories c WHERE b.bId = c.bId AND c.category = 'semweb')
GROUP BY b.bId
HAVING COUNT( b.bId ) =2
Toxi提出了一种三表结构。通过“tagmap”表,书签和标签是n对m相关的。每个标签可以与不同的书签一起使用,反之亦然。这个数据库架构也被WordPress使用。查询与“scuttle”解决方案几乎相同。
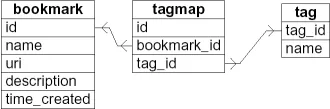
交集(AND)
查询“bookmark+webservice+semweb”
SELECT b.*
FROM tagmap bt, bookmark b, tag t
WHERE bt.tag_id = t.tag_id
AND (t.name IN ('bookmark', 'webservice', 'semweb'))
AND b.id = bt.bookmark_id
GROUP BY b.id
HAVING COUNT( b.id )=3
联合(或)查询“bookmark|webservice|semweb”
SELECT b.*
FROM tagmap bt, bookmark b, tag t
WHERE bt.tag_id = t.tag_id
AND (t.name IN ('bookmark', 'webservice', 'semweb'))
AND b.id = bt.bookmark_id
GROUP BY b.id
减法(排除) 针对“bookmark+webservice-semweb”进行查询,即:书签 AND Web服务 AND NOT 语义Web。
SELECT b. *
FROM bookmark b, tagmap bt, tag t
WHERE b.id = bt.bookmark_id
AND bt.tag_id = t.tag_id
AND (t.name IN ('Programming', 'Algorithms'))
AND b.id NOT IN (SELECT b.id FROM bookmark b, tagmap bt, tag t WHERE b.id = bt.bookmark_id AND bt.tag_id = t.tag_id AND t.name = 'Python')
GROUP BY b.id
HAVING COUNT( b.id ) =2
你的三个表方案没有问题。
另一个选择是限制可以应用于文章的标签数量(例如SO中的5个),并将这些标签直接添加到您的文章表中。
规范化数据库既有优点也有缺点,就像将事物硬编码到一个表中一样,也有优点和缺点。
并不意味着你不能两者都做。重复信息违反关系型数据库范例,但如果目标是性能,你可能需要打破这些范例。
您提出的三个表实现可以用于标记。
然而,Stack Overflow使用不同的实现。他们将标记存储到帖子表中的varchar列中,并使用全文索引来获取与标记匹配的帖子。例如posts.tags = "algorithm system tagging best-practices"。我确信Jeff在某个地方提到过这一点,但我忘记了在哪里。
我能想到的解决标签和文章之间多对多关系的最佳方法,如果不是唯一可行的方法,那么也是最好的。所以我的投票是“是的,它仍然是最好的”。不过,我对任何其他替代方案也很感兴趣。

and条件将更有效率(LIKE '%|a|%|c|%|f|%)。sql和mysql这样的标签,因为LIKE "%sql%"也会返回mysql的结果。应该是LIKE "%|sql|%"
我知道搜索是非索引的,但仍然可能已经对与文章相关的其他列进行了索引,如作者/日期时间,否则将导致完整表扫描。CREATE TABLE Tags (
tag VARHAR(...) NOT NULL,
bid INT ... NOT NULL,
PRIMARY KEY(tag, bid),
INDEX(bid, tag)
)
注意: