目前我正在学习Apache Spark和Apache Ignite框架。
本文Ignite vs.Spark描述了它们之间的一些主要差异。但我意识到我仍然不理解它们的目的。
我的意思是,Spark在哪些问题上比Ignite更可取,反之亦然?
目前我正在学习Apache Spark和Apache Ignite框架。
本文Ignite vs.Spark描述了它们之间的一些主要差异。但我意识到我仍然不理解它们的目的。
我的意思是,Spark在哪些问题上比Ignite更可取,反之亦然?
我认为Spark是适用于交互式分析的好产品,而Ignite则更适合实时分析和高性能事务处理。Ignite通过提供高效且可扩展的内存键值存储,以及对数据进行索引、查询和运行计算的丰富功能,实现这一目标。
Ignite的另一个常见用途是分布式缓存,通常用于提高与关系数据库或任何其他数据源交互的应用程序的性能。
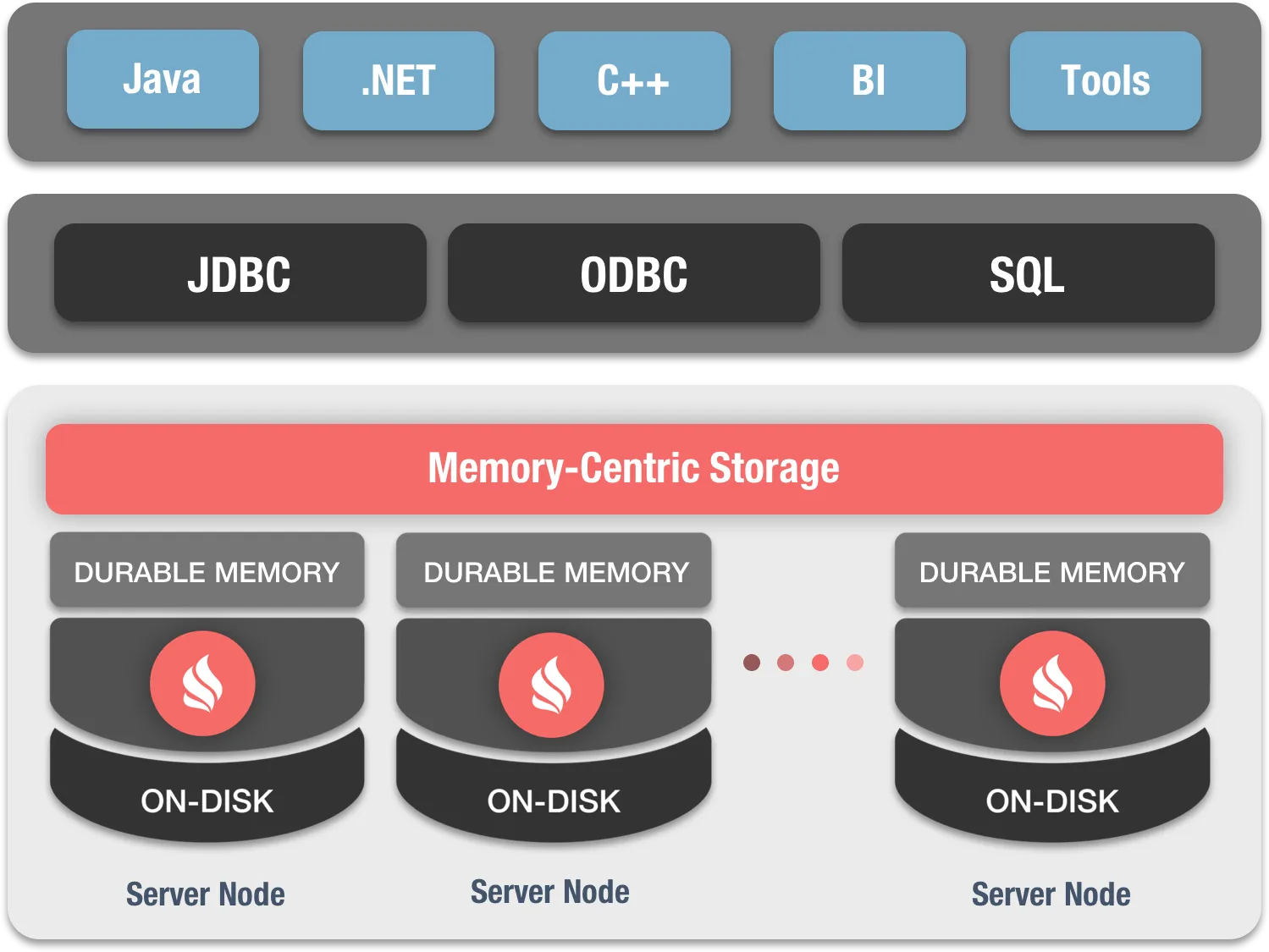
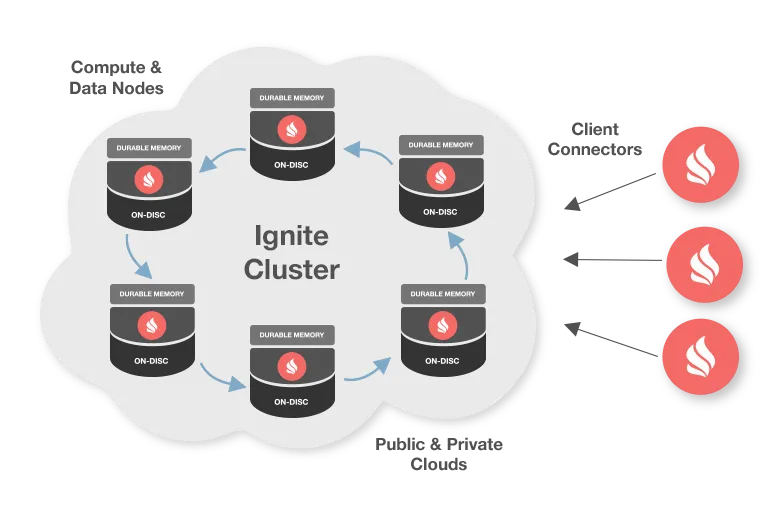
Apache Ignite是一个分布式内存平台,可在大规模数据集上进行实时计算和事务处理。Ignite是数据源不可知的平台,可以在多个服务器上分发和缓存数据以提供前所未有的处理速度和应用程序可扩展性。
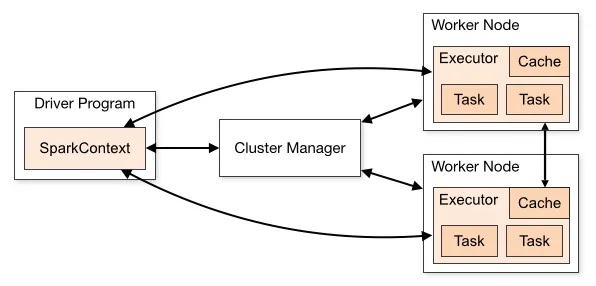
Apache Spark(集群计算框架)是一个快速的内存数据处理引擎,具有表达式开发API,允许数据工作者高效地执行需要快速迭代访问数据集的流式处理、机器学习或SQL工作负载。 通过允许用户程序将数据加载到群集的内存中并重复查询它,Spark非常适合高性能计算和机器学习算法。
一些概念上的区别:
Spark不存储数据,它从其他存储(通常是基于磁盘的存储)中加载数据进行处理,然后在处理完成后丢弃该数据。Ignite提供了一个分布式内存键值存储(分布式缓存或数据网格),具有ACID事务和SQL查询功能。
Spark用于非事务性的只读数据(RDD不支持原地变化),而Ignite既支持非事务性(OLAP)负载,也支持完全符合ACID标准的事务性(OLTP)负载。
Ignite完全支持可以是“无数据”的纯计算负载(HPC/MPP)。Spark基于RDD,并仅适用于数据驱动的负载。
结论:
Ignite和Spark都是内存计算解决方案,但它们针对不同的用例。
在许多情况下,它们一起使用以实现更优异的结果:
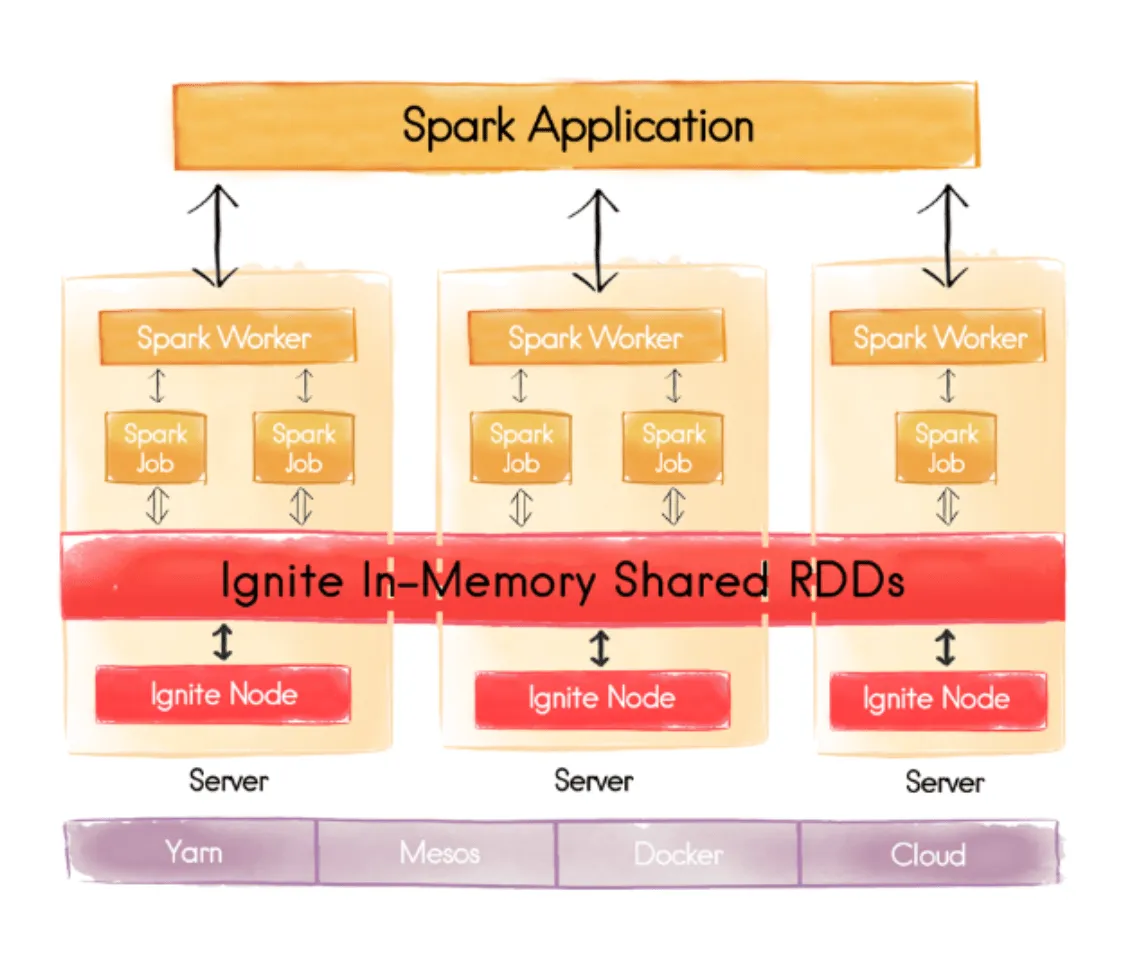
Ignite可以提供共享存储,因此状态可以从一个Spark应用程序或作业传递到另一个应用程序或作业。
Ignite可以提供带索引的SQL,因此可以加速Spark SQL超过1,000倍(Spark不会对数据进行索引)。
当处理文件而不是RDD时,Apache Ignite In-Memory File System(IGFS)还可以在Spark作业和应用程序之间共享状态。
是的,Spark和Ignite可以一起使用。
Ignite vs. Spark
Ignite是一个内存分布式数据库,更专注于数据存储和处理事务更新,然后提供客户端请求服务。Apache Spark是一个面向分析、ML、Graph和ETL特定负载的MPP计算引擎。
Apache Spark是一个通用的集群计算系统。它是优化的引擎,支持一般执行图。它还支持丰富的高级工具,包括Spark SQL用于SQL和结构化数据处理,MLlib用于机器学习,GraphX用于图形处理和Spark Streaming。
Ignite是一个以内存为中心的分布式数据库、缓存和处理平台,可用于交易型、分析型和流式工作负载,以内存速度提供PB级别的吞吐量。Ignite还包括一流的集群管理和操作支持、集群感知消息传递和零部署技术。Ignite还提供对跨内存和可选数据源的全ACID事务的支持。
SQL概述
部署拓扑
我回答这个问题有点晚,但让我试着分享我的看法。
对于企业应用程序来说,Ignite可能还没有准备好用于生产,因为一些重要的功能,如安全性,只在Gridgain(Ignite的包装器)中可用。
完整的功能列表可以从下面的链接找到。
Spark doesn’t store data, it loads data for processing from other storages, usually disk-based, and then discards the data when the processing is finished. Ignite, on the other hand, provides a distributed in-memory key-value store (distributed cache or data grid) with ACID transactions and SQL querying capabilities.
Spark is for non-transactional, read-only data (RDDs don’t support in-place mutation), while Ignite supports both non-transactional (OLAP) payloads as well as fully ACID compliant transactions (OLTP)
Ignite fully supports pure computational payloads (HPC/MPP) that can be “dataless”. Spark is based on RDDs and works only on data-driven payloads.