使用
LabelEncoder对特征进行编码,无论是有序的还是无序的,都不是一个好主意!请避免这种做法。
实际上,文档中明确指出,这种编码方法旨在对标签进行编码,正如其名称所示:
应使用此转换器来编码目标值,即 y,而不是输入 X。
正如您在问题中正确指出的那样,将隐含的ordinal feature的序数映射到错误的比例上,将会对模型的性能产生非常负面的影响(即与特征的相关性成比例)。对于categorical feature也是同样的道理,只是原始特征没有序数。
一种直观的思考方式,是以decision tree设置其边界的方式。在训练期间,决策树将学习在每个节点处设置最佳特征,以及一种最佳阈值,在此阈值下,未见过的样本将遵循一个分支或另一个分支,具体取决于这些值。
如果我们使用简单的LabelEncoder编码顺序特征,则可能导致具有1表示warm,2可能会转化为hot,而0则代表boiling的特征。在这种情况下,结果将是一棵具有过多分裂的树,因此对于应该更简单的模型而言,其复杂度会更高。
相反,正确的方法是使用OrdinalEncoder,并为序数特征定义适当的映射方案。或者在具有分类特征的情况下,我们应该考虑使用OneHotEncoder或Category Encoders中提供的各种编码器。
尽管直观地看到这是一个坏主意,比简单的文字更易理解。
我们使用一个简单的例子来说明上述内容,包括两个序数特征,其中一个包含学生为备考考试花费的小时数的范围,另一个是所有先前作业的平均成绩,以及指示考试是否通过的目标变量。我已将数据帧的列定义为pd.Categorical:
df = pd.DataFrame(
{'Hours of dedication': pd.Categorical(
values = ['25-30', '20-25', '5-10', '5-10', '40-45',
'0-5', '15-20', '20-25', '30-35', '5-10',
'10-15', '45-50', '20-25'],
categories=['0-5', '5-10', '10-15', '15-20',
'20-25', '25-30','30-35','40-45', '45-50']),
'Assignments avg grade': pd.Categorical(
values = ['B', 'C', 'F', 'C', 'B',
'D', 'C', 'A', 'B', 'B',
'B', 'A', 'D'],
categories=['F', 'D', 'C', 'B','A']),
'Result': pd.Categorical(
values = ['Pass', 'Pass', 'Fail', 'Fail', 'Pass',
'Fail', 'Fail','Pass','Pass', 'Fail',
'Fail', 'Pass', 'Pass'],
categories=['Fail', 'Pass'])
}
)
定义 pandas 的分类列的优势在于,我们可以为其类别建立顺序,如前所述。这样可以基于建立的顺序进行更快速的排序,而不是按字典顺序排序。它还可以作为一种简单的方式,根据它们的顺序获取不同类别的代码。
因此,我们将使用的数据框如下:
print(df.head())
Hours_of_dedication Assignments_avg_grade Result
0 20-25 B Pass
1 20-25 C Pass
2 5-10 F Fail
3 5-10 C Fail
4 40-45 B Pass
5 0-5 D Fail
6 15-20 C Fail
7 20-25 A Pass
8 30-35 B Pass
9 5-10 B Fail
可以使用以下方式获取相应的类别代码:
X = df.apply(lambda x: x.cat.codes)
X.head()
Hours_of_dedication Assignments_avg_grade Result
0 4 3 1
1 4 2 1
2 1 0 0
3 1 2 0
4 7 3 1
5 0 1 0
6 3 2 0
7 4 4 1
8 6 3 1
9 1 3 0
现在让我们拟合一个
DecisionTreeClassifier,看看树是如何定义分裂的:
from sklearn import tree
dt = tree.DecisionTreeClassifier()
y = X.pop('Result')
dt.fit(X, y)
我们可以使用
plot_tree可视化树结构:
t = tree.plot_tree(dt,
feature_names = X.columns,
class_names=["Fail", "Pass"],
filled = True,
label='all',
rounded=True)

就这些吗??嗯...是的!实际上,我已经将功能设置成这样,使得在投入时间特征和考试是否通过之间存在简单而明显的关系,清楚地表明问题应该非常容易建模。
现在让我们尝试通过直接使用编码方案来对所有特征进行编码,我们可以通过例如
LabelEncoder获得该方案,因此忽略特征的实际序数,仅随机分配一个值:
df_wrong = df.copy()
df_wrong['Hours_of_dedication'].cat.set_categories(
['0-5','40-45', '25-30', '10-15', '5-10', '45-50','15-20',
'20-25','30-35'], inplace=True)
df_wrong['Assignments_avg_grade'].cat.set_categories(
['A', 'C', 'F', 'D', 'B'], inplace=True)
rcParams['figure.figsize'] = 14,18
X_wrong = df_wrong.drop(['Result'],1).apply(lambda x: x.cat.codes)
y = df_wrong.Result
dt_wrong = tree.DecisionTreeClassifier()
dt_wrong.fit(X_wrong, y)
t = tree.plot_tree(dt_wrong,
feature_names = X_wrong.columns,
class_names=["Fail", "Pass"],
filled = True,
label='all',
rounded=True)
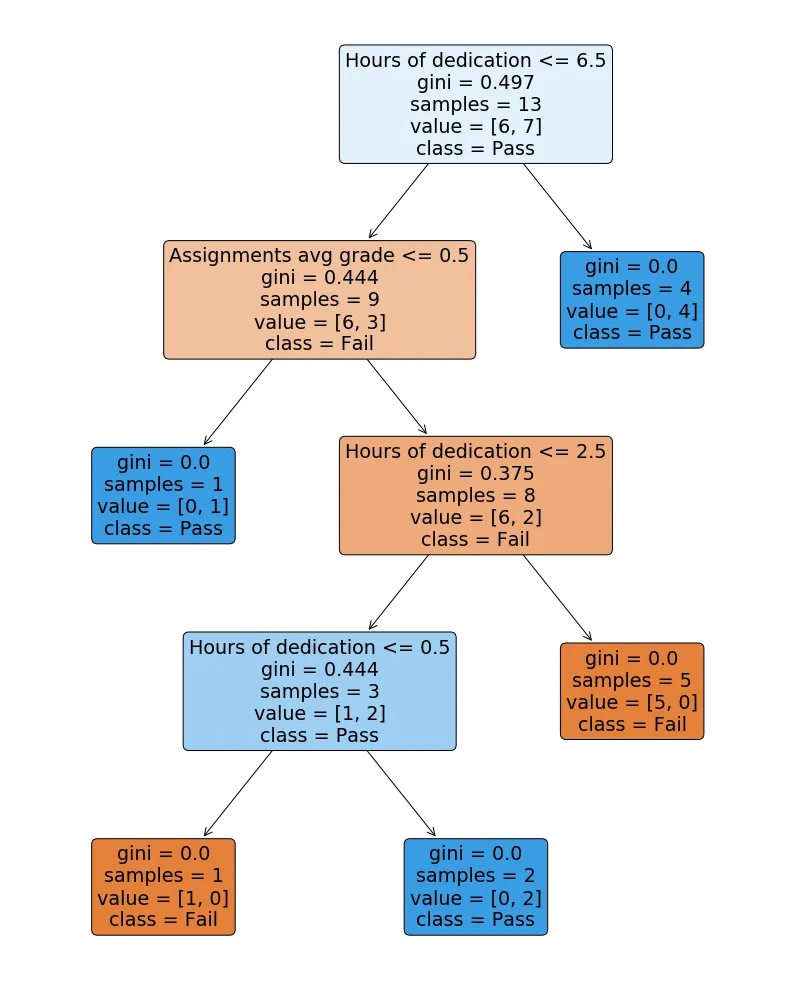
如预期所示,对于我们试图建模的简单问题,树结构比必要的复杂得多。为了使树正确地预测所有训练样本,它已经扩展到深度为4的节点,而实际上一个单一节点就足够了。
这将意味着分类器很可能会过度拟合,因为我们正在大幅增加复杂性。通过修剪树和调整必要的参数以防止过度拟合,我们也无法解决问题,因为我们通过错误编码特征添加了太多噪音。
因此,总结一下,保留特征编码后的序数是至关重要的,否则,正如这个例子所清楚表明的那样,我们将失去它们所有可预测的力量,并向我们的模型添加噪音。