我正在尝试创建一个表来存储DynamoDB中的发票行项目。假设该项目由CompanyCode、InvoiceNumber和LineItemId、金额以及其他行项目细节定义。
唯一的项目由前3个属性的组合定义。对于不同的项目,这些属性中的任意2个可以相同。我应该选择什么作为哈希属性和范围属性?
我正在尝试创建一个表来存储DynamoDB中的发票行项目。假设该项目由CompanyCode、InvoiceNumber和LineItemId、金额以及其他行项目细节定义。
唯一的项目由前3个属性的组合定义。对于不同的项目,这些属性中的任意2个可以相同。我应该选择什么作为哈希属性和范围属性?
为提高效率,我建议采用完全不同的设计。对于NoSQL数据库(DynamoDB也不例外),我们始终需要先考虑访问模式。此外,如果可能的话,我们应该努力将所有数据放在同一张表格和几个索引中。从OP及其评论中获得的信息,这是两种访问模式:
现在我们想知道什么是好的主键?这转化为了问题,什么是好的分区键(PK)和排序键(SK),我们需要创建哪些二级索引以及是何种类型的(本地或全局)?以下是一些提醒:
KeyConditionExpression选项提供的排序运算符集和之间的所有内容(其中之一是函数begins_with(a, substr))FilterExpression很明显,我们正在处理需要进行建模并适合于同一张表中的多个实体。为了满足表上唯一的分区键条件,CompanyCode成为自然的分区键 - 所以我会确保它是唯一的。如果不是,则需要问自己如何对第二个访问模式进行建模?
假设我们已经确定了 CompanyCode 的唯一性,让我们简化并说它以电子邮件的形式出现(或者可能是域名或只是一个代码,但我将使用电子邮件进行演示)。
我提出如下图所示的设计: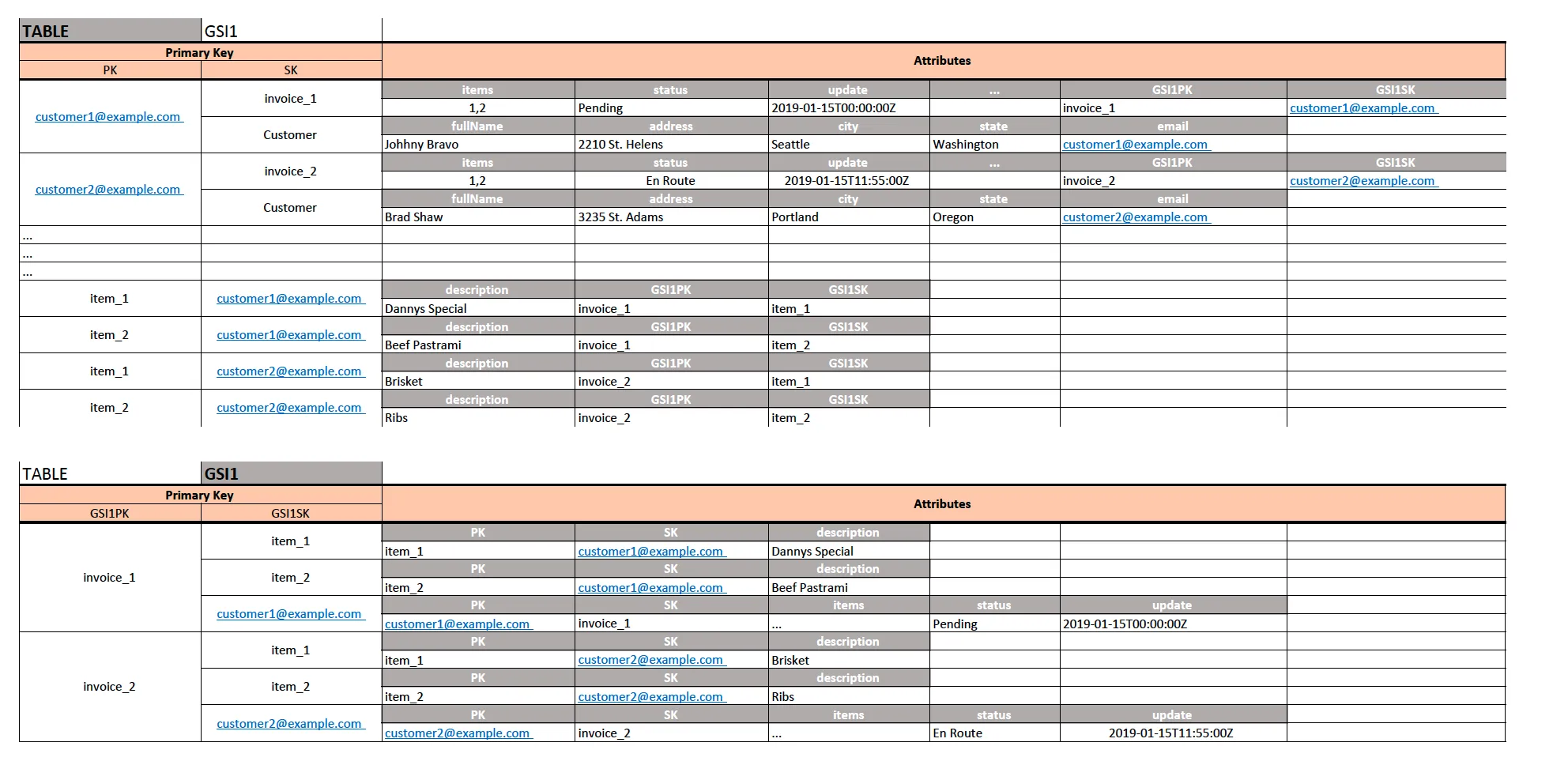
CompanyCode和InvoiceNumber,可以存储有关该公司的发票的所有属性。Customer的记录,这使我能够存储有关公司的所有属性。 InvoiceNumber ),而GSI1SK是我的表PK( CompanyCode )。 LineItemId 和 CompanyCode (仍然是唯一的) InvoiceNumber ,而我的GSI1SK是 LineItemId ,它是表的PK,因此与Invoice实体项相同。现在支持以下访问模式:
CompanyCode = X ,并使用键条件表达式在排序键 InvoiceNumber 上使用 = 运算符。如果我想获取与该发票相关的所有项目,则将ProjectionExpression的 Items 属性进行投影。 BatchGetItem API调用(使用我的唯一复合键 LineItemId + CompanyCode )获取属于特定客户的特定发票的所有项目。(这带有一些BatchGetItem API的限制)CompanyCode=X查询,并使用KeyConditionExpression对SK进行筛选,使用begins_with(a, substr)函数/操作符以获取给定公司/客户的所有发票,而不是关于该公司的元数据。InvoiceNumber,我可以轻松选择属于该特定发票的所有行项目。请记住:全局二级索引中的键值不需要唯一 - 因此在我的GSI1中,我可以轻松地拥有invoice_1 -> (item_1,item_2)和另一个invoice_1 -> (item_1,item_2),但在GSI中两个项之间的区别在SK中(它将与不同的CompanyCode相关联,但出于演示目的,我使用了invoice_1和invoice_2)。我认为 @georgeaf99提供的第一个选项 不可行,因为如果您按照这种方式操作,那么CompanyCode必须在表中是唯一的。因此,每个公司只允许一个项目。我认为第二个解决方案是唯一真正可行的方法。
您可以将CompanyCode用作哈希键,然后所有其他组合成使项唯一的字段(在本例中是InvoiceNumber和LineItemId)需要以某种方式组合成一个值(例如连接使用字段分隔符),这将是您的区间键。不幸的是,这有点丑陋,但这就是像DynamoDB这样的NoSQL数据库的性质。但是,它将允许您成功存储具有正确唯一性的记录。当读取记录时,如果您不想将组合字段解析回其各个部分,则必须添加额外的单独字段以获取InvoiceNumber和LineItemID。
我相信你已经明白了,主键(散列+范围)最多只能有两个属性。因此,根据你执行的查询类型和数据大小,你可以以不同的方式构建表格。
(优化了你上述提到的查询类型:仅使用CompanyCode和所有3个属性)
小/中型数据集的最佳解决方案:
CompanyCodeCompanyCode进行查询,然后在其他两个属性上筛选结果大型数据集的最佳解决方案:
CompanyCodeInvoiceNumber+LineItemId