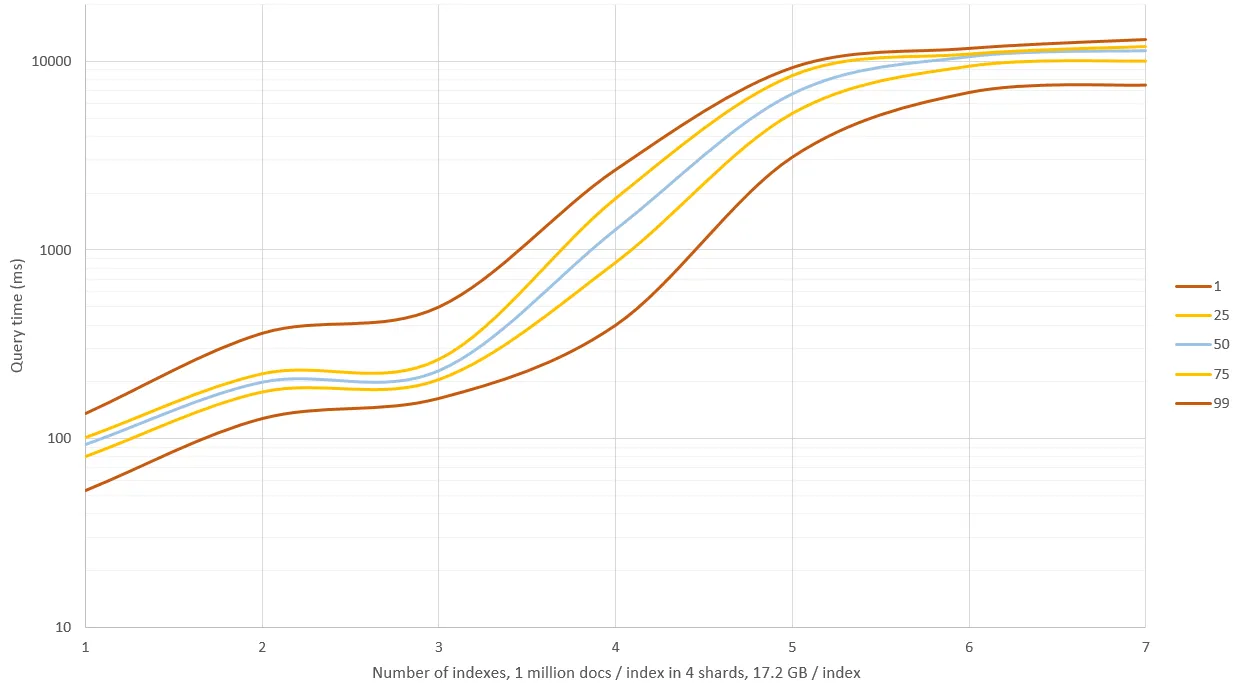
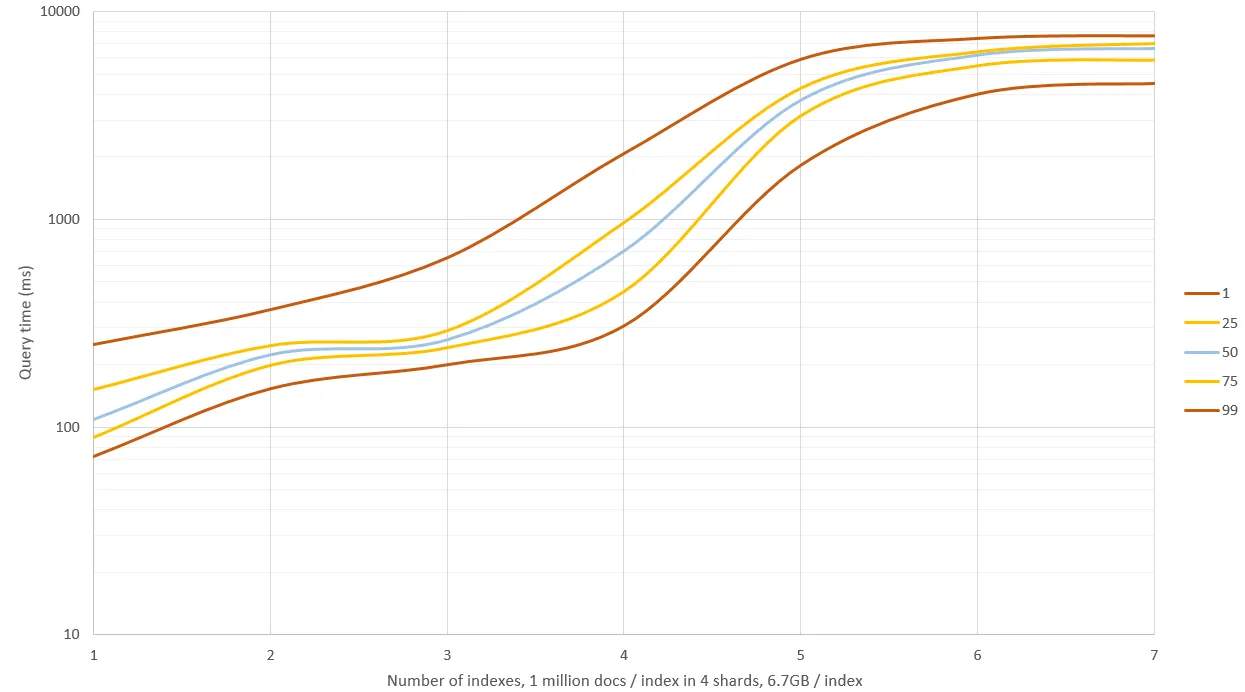
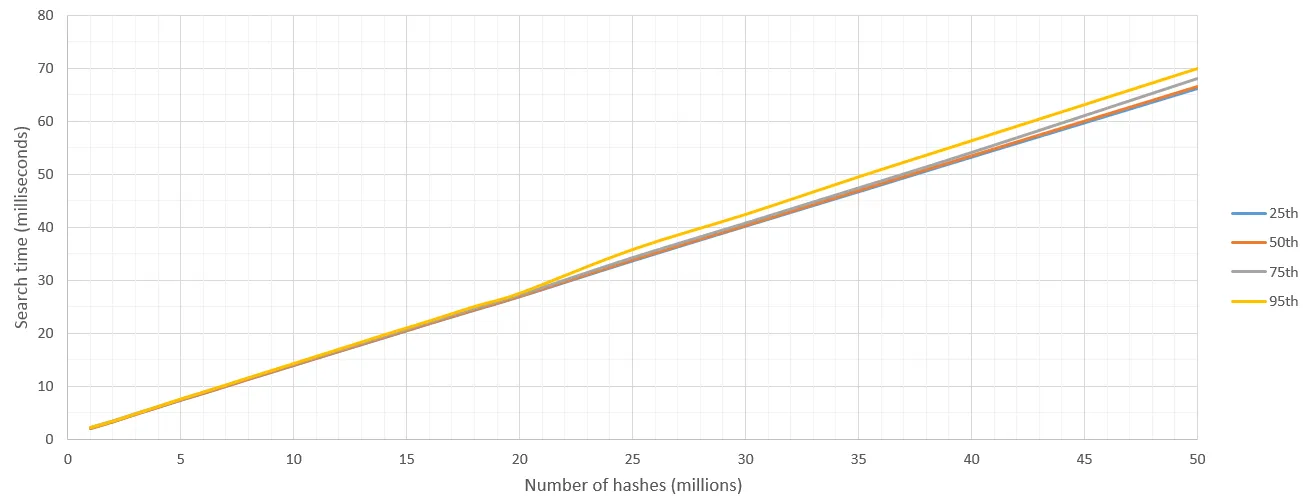
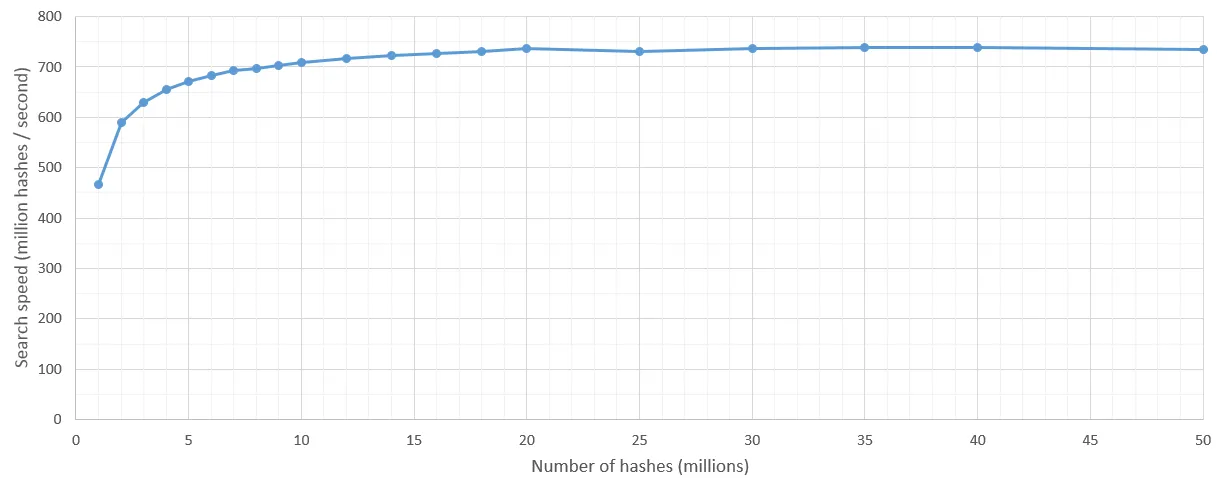
类似图像搜索问题
- 数百万张图片通过pHash进行哈希处理并存储在 Elasticsearch 中。
- 格式为“11001101...11”(长度为64),但可以更改(最好不要)。
给定主题图像的哈希值“100111..10”,我们希望在 Elasticsearch 索引中找到所有汉明距离小于8的相似图像哈希值。
当然,查询可能会返回距离大于8的图像,Elasticsearch 中的脚本或外部脚本可以过滤结果集。但总搜索时间必须在1秒左右。
我们当前的映射
每个文档都有一个嵌套的images字段,其中包含图像哈希:
{
"images": {
"type": "nested",
"properties": {
"pHashFingerprint": {"index": "not_analysed", "type": "string"}
}
}
}
我们的低效解决方案
事实: Elasticsearch 模糊查询仅支持最大编辑距离为 2。
我们使用自定义分词器将 64 位字符串拆分成 4 组 16 位,并使用四个模糊查询进行四组搜索。
分析器:
{
"analysis": {
"analyzer": {
"split4_fingerprint_analyzer": {
"type": "custom",
"tokenizer": "split4_fingerprint_tokenizer"
}
},
"tokenizer": {
"split4_fingerprint_tokenizer": {
"type": "pattern",
"group": 0,
"pattern": "([01]{16})"
}
}
}
}
新的字段映射:
"index_analyzer": "split4_fingerprint_analyzer",
然后查询:
{
"query": {
"filtered": {
"query": {
"nested": {
"path": "images",
"query": {
"bool": {
"minimum_should_match": 2,
"should": [
{
"fuzzy": {
"phashFingerprint.split4": {
"value": "0010100100111001",
"fuzziness": 2
}
}
},
{
"fuzzy": {
"phashFingerprint.split4": {
"value": "1010100100111001",
"fuzziness": 2
}
}
},
{
"fuzzy": {
"phashFingerprint.split4": {
"value": "0110100100111001",
"fuzziness": 2
}
}
},
{
"fuzzy": {
"phashFingerprint.split4": {
"value": "1110100100111001",
"fuzziness": 2
}
}
}
]
}
}
}
},
"filter": {}
}
}
}
问题是,即使在添加其他特定于域的过滤器以减少初始集合后,此查询仍会返回成千上万的结果。脚本需要进行太多计算来重新计算汉明距离,因此查询可能需要几分钟。
如预期的那样,如果将
minimum_should_match 增加到 3 和 4,只返回必须找到的图像子集,但结果集较小且速度快。使用 minimum_should_match == 3 返回的图片不足所需的图片的95%,但我们需要像 minimum_should_match == 2那样达到100%(或99.9%)。我们尝试了类似的n-grams方法,但无法解决结果太多的问题。
是否有其他数据结构和查询的解决方案?
编辑:
我们注意到评估过程中存在错误,并且
minimum_should_match == 2 返回了100%的结果。但是之后处理时间平均为5秒。我们将看看优化脚本是否值得。