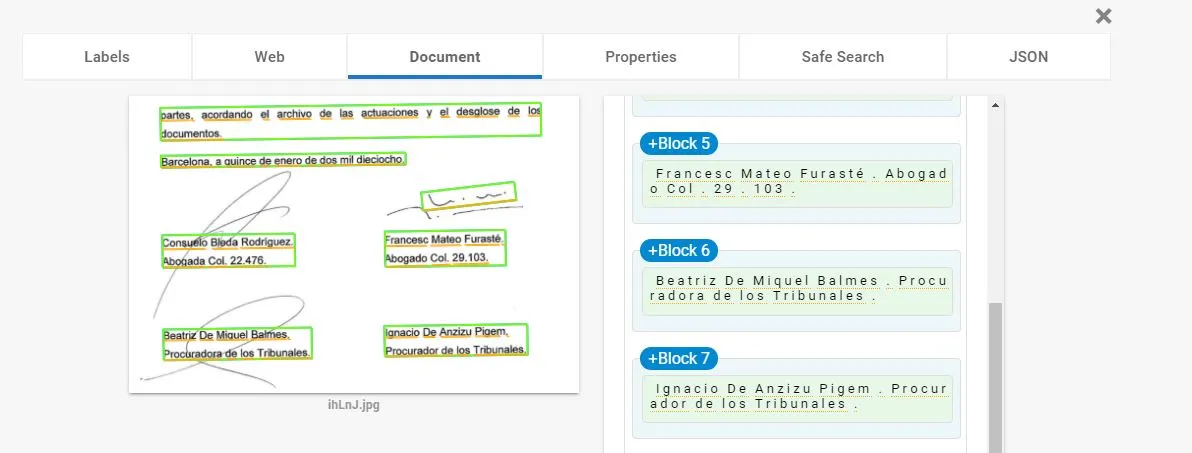
我正在尝试对一份扫描文件进行OCR识别,其中包含手写签名。请参见下面的图像。

我的问题很简单,是否有办法在忽略签名的情况下使用OCR提取人名?当我运行Tesseract OCR时,它无法检索到这些名称。我尝试了灰度处理/模糊处理/阈值化,并使用下面的代码,但没有成功。有什么建议吗?
image = cv2.imread(file_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = cv2.GaussianBlur(image, (5, 5), 0)
image = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]