import tensorflow as tf
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten, Conv2D, MaxPooling2D
import pickle
import numpy as np
from keras.models import model_from_json
from keras.models import load_model
import matplotlib.pyplot as plt
# Opening the files about data
X = pickle.load(open("X.pickle", "rb"))
y = pickle.load(open("y.pickle", "rb"))
# normalizing data (a pixel goes from 0 to 255)
X = X/255.0
# Building the model
model = Sequential()
# 3 convolutional layers
model.add(Conv2D(32, (3, 3), input_shape = X.shape[1:]))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.9))
# 5 hidden layers
model.add(Flatten())
model.add(Dense(128))
model.add(Activation("relu"))
model.add(Dense(128))
model.add(Activation("relu"))
model.add(Dense(128))
model.add(Activation("relu"))
model.add(Dense(128))
model.add(Activation("relu"))
model.add(Dense(128))
model.add(Activation("relu"))
# The output layer with 7 neurons, for 7 classes
model.add(Dense(13))
model.add(Activation("softmax"))
# Compiling the model using some basic parameters
model.compile(loss="sparse_categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"])
# Training the model, with 40 iterations
# validation_split corresponds to the percentage of images used for the validation phase compared to all the images
print("X = " + str(len(X)))
print("y = " + str(len(y)))
history = model.fit(X, y, batch_size=32, epochs=1000, validation_split=0.1)
# Saving the model
model_json = model.to_json()
with open("model.json", "w") as json_file :
json_file.write(model_json)
model.save_weights("model.h5")
print("Saved model to disk")
model.save('CNN.model')
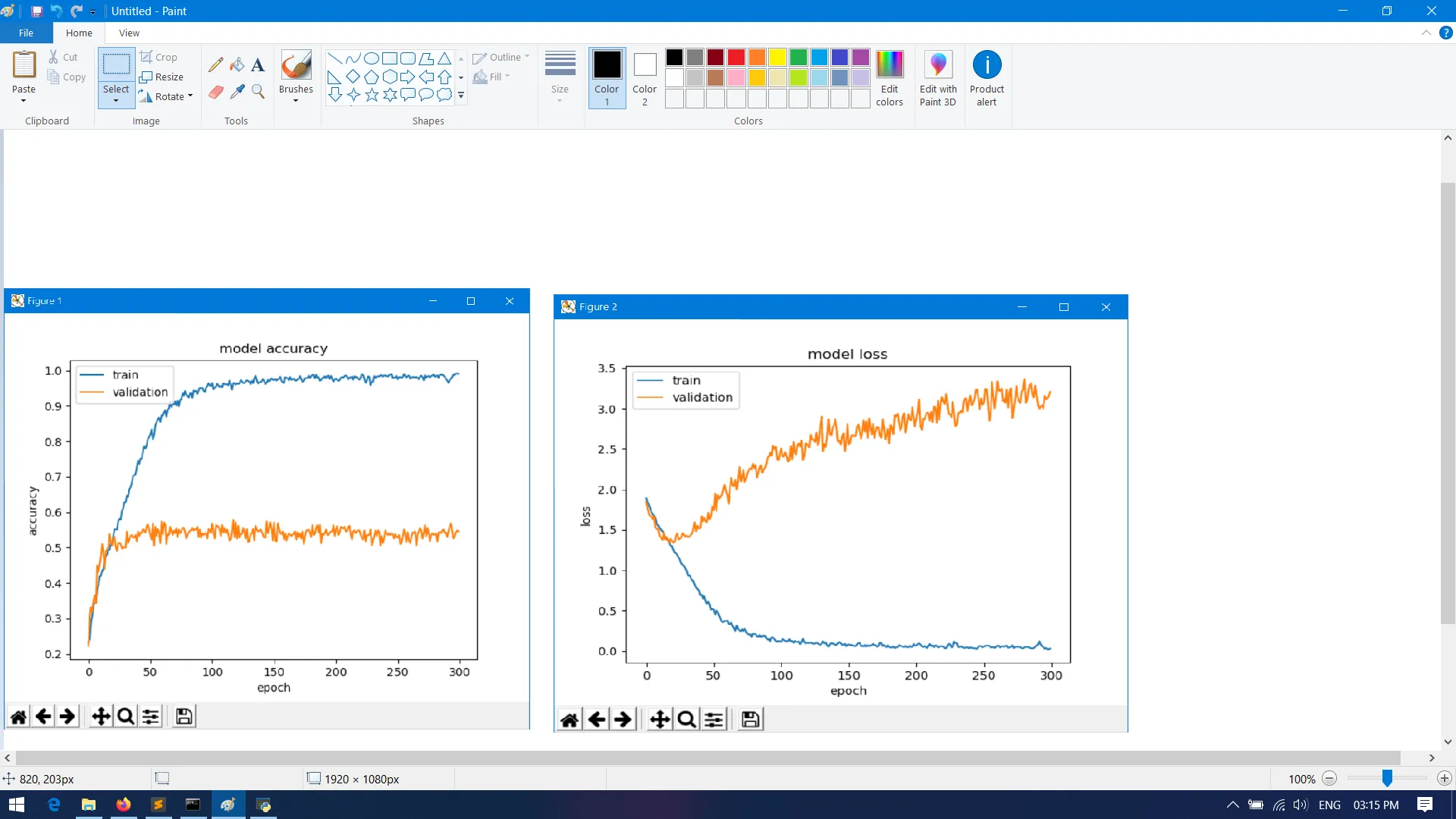
# Printing a graph showing the accuracy changes during the training phase
print(history.history.keys())
plt.show()
plt.plot(history.history['accuracy'])
plt.plot(history.history['loss'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
问题在于,我的训练损失较低,但验证准确率非常高。而验证的准确性也极低。我该如何解决这个问题?我尝试将丢弃值增加到0.9,但损失仍然很高。我还尝试使用线性函数进行激活,但无济于事。
请帮忙。