这是一个看似简单的问题,但我一开始并没有认为如此。经过一个小时的思考,我也不太确定了!
我有一个Python datetime对象列表,我想将它们绘制成图表。x轴的值是年份和月份,y轴的值是在该月发生的日期对象数量。
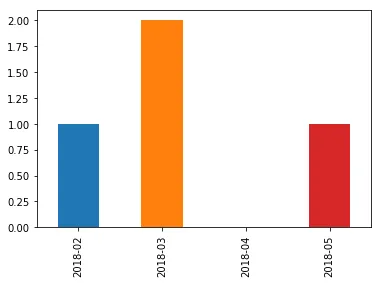
也许一个例子会更好地说明这个问题(dd/mm/yyyy):
[28/02/2018, 01/03/2018, 16/03/2018, 17/05/2018]
-> ([02/2018, 03/2018, 04/2018, 05/2018], [1, 2, 0, 1])
我的第一次尝试是简单地按日期和年份分组,类似于:
import itertools
group = itertools.groupby(dates, lambda date: date.strftime("%b/%Y"))
graph = zip(*[(k, len(list(v)) for k, v in group]) # format the data for graphing
你可能已经注意到,这只会按照列表中已有的日期进行分组。在上面的示例中,四月份没有出现任何日期将被忽略。
接下来,我尝试查找开始和结束日期,并循环遍历它们之间的所有月份:
import datetime
data = [[], [],]
for year in range(min_date.year, max_date.year):
for month in range(min_date.month, max_date.month):
k = datetime.datetime(year=year, month=month, day=1).strftime("%b/%Y")
v = sum([1 for date in dates if date.strftime("%b/%Y") == k])
data[0].append(k)
data[1].append(v)
当然,这仅在
min_date.month小于max_date.month的情况下才有效,如果它们跨越多年,则不一定成立。而且,这种方法相当丑陋。有没有一种优雅的方法来解决这个问题呢?
谢谢。
编辑:明确一点,这些日期是
datetime对象,而不是字符串。它们在这里看起来像字符串只是为了可读性。