我正在制作一个Python网络爬虫程序来玩维基百科游戏。
如果您不熟悉这个游戏:
1. 从维基百科的某篇文章开始 2. 选择一个目标文章 3. 仅通过点击wiki/链接,尝试从起始文章到达目标文章
我的处理过程如下:
1. 输入起始文章和目标文章 2. 获取链接到目标文章的文章列表 3. 在避免访问已经被访问的页面的情况下,在起始文章开始执行广度优先搜索找到的链接 4. 检查目标文章是否在当前页面上:如果是,则返回
我意识到,通过从目标页面抓取所有链接,我可以获得到达目标的链接,但wiki/链接是单向的:仅因为目标链接到某个页面并不意味着该页面链接到目标。
我如何获取链接到目标的文章列表?
如果您不熟悉这个游戏:
1. 从维基百科的某篇文章开始 2. 选择一个目标文章 3. 仅通过点击wiki/链接,尝试从起始文章到达目标文章
我的处理过程如下:
1. 输入起始文章和目标文章 2. 获取链接到目标文章的文章列表 3. 在避免访问已经被访问的页面的情况下,在起始文章开始执行广度优先搜索找到的链接 4. 检查目标文章是否在当前页面上:如果是,则返回
path_crawler_took+goal_article
5. 检查链接到目标文章的任何文章是否在当前页面上。如果其中一个是,则返回path_crawler_took+intermediate_article+goal
我遇到了一个问题,程序返回了一个路径,但是这个路径并没有真正地链接到目标。def get_all_links(source):
source = source[:source.find('Edit section: References')]
source = source[:source.find('id="See_also"')]
links=findall('\/wiki\/[^\(?:/|"|\#)]+',source)
return list(set(['http://en.wikipedia.org'+link for link in links if is_good(link) and link]))
links_to_goal = get_all_links(goal)
我意识到,通过从目标页面抓取所有链接,我可以获得到达目标的链接,但wiki/链接是单向的:仅因为目标链接到某个页面并不意味着该页面链接到目标。
我如何获取链接到目标的文章列表?
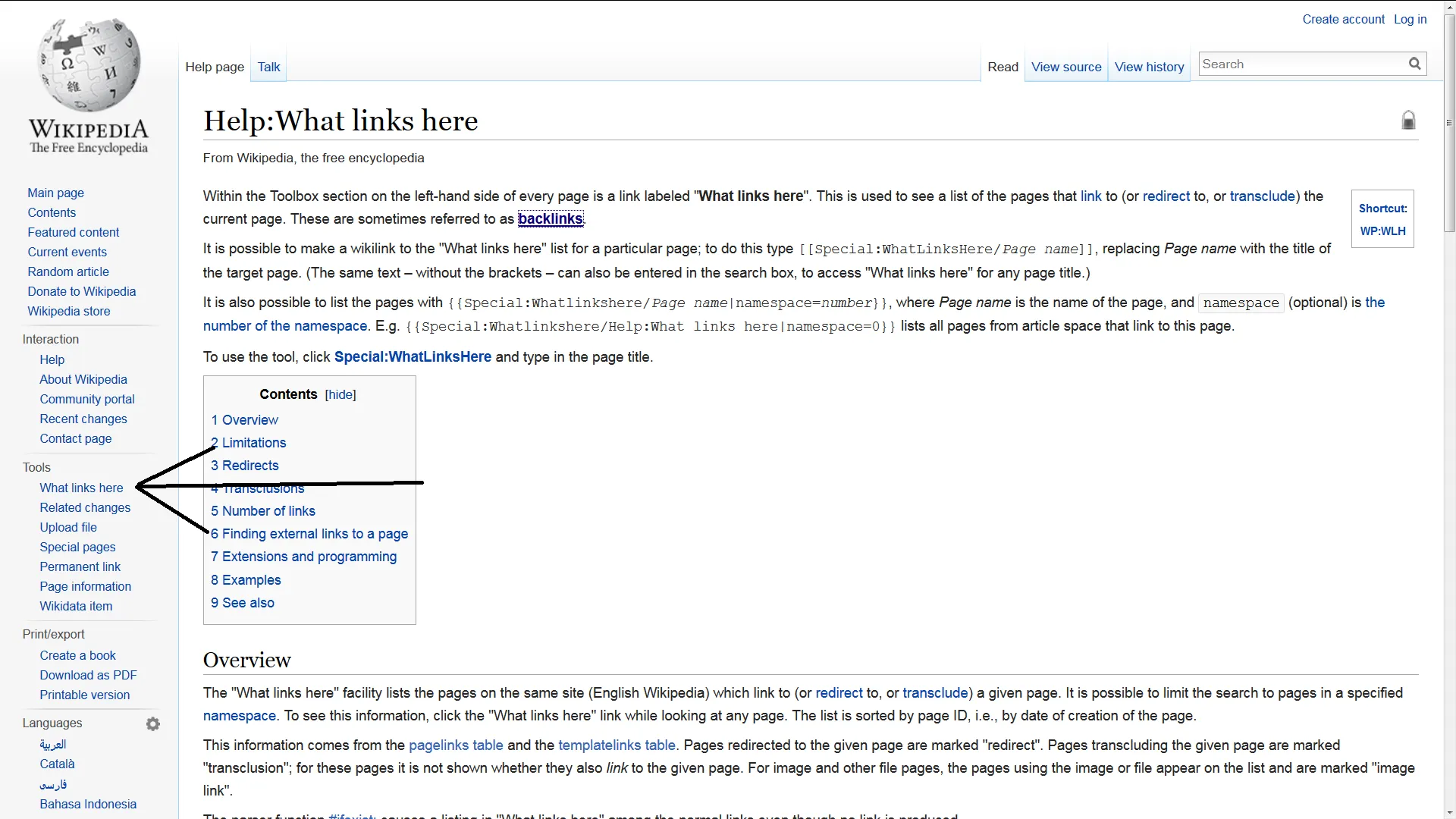 您可以简单地从目标反向链接页面上抓取所有链接。
您可以简单地从目标反向链接页面上抓取所有链接。