我正在使用mod security规则https://github.com/SpiderLabs/owasp-modsecurity-crs来清理用户输入数据。我发现CPU飙升,匹配用户输入和mod security规则正则表达式有延迟。总体上,它包含500多个正则表达式,用于检查不同类型的攻击(如xss、badrobots、通用和sql)。对于每个请求,我都会通过所有参数,并检查所有这些500个正则表达式。我正在使用
Matcher.find来检查参数。在这种情况下,一些参数会出现无限循环,我用以下技术解决了这个问题。
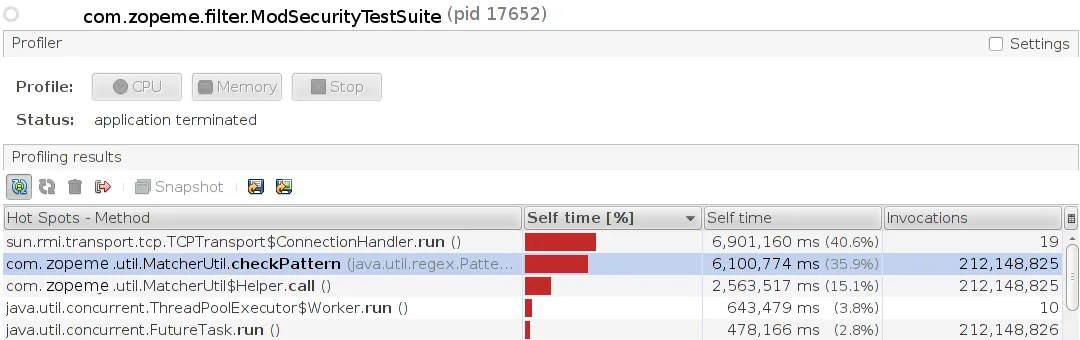
清理用户请求大约需要~500毫秒,CPU%飙升。我使用test suite runner和visualvm.java.net进行了分析。
Cpu Profile 输出
请帮助我降低CPU使用率%和负载平均值?
checkPattern总共被调用了212148825次,总计时间为6100774毫秒,每次调用平均耗时0.02毫秒。我认为这里没有性能问题,而且绝对没有每次调用500毫秒的证据。 - user330315jstack -l获取了线程转储,并使用thread -H -b -p <process id>查找最大消耗线程,并将其ID转换为十六进制代码。高CPU(50%)的线程处于Matcher.find的可运行状态。 - kannanrbkMatcher.find调用其他方法,由于分析器的默认过滤规则而未显示。更改这些规则以允许查看JDK方法内部可以揭示大部分时间(意味着CPU负载)花费在匹配的哪个位置。 - Holger