简单来说,交叉验证和网格搜索有什么区别?网格搜索是如何工作的?我应该先做交叉验证还是先做网格搜索?
6个回答
105
交叉验证是指保留数据的一部分用于评估模型。有不同的交叉验证方法。最简单的概念是只取数据的70%(这里只是举个例子,不一定要是70%)作为训练数据,剩下的30%用来评估模型的表现。之所以需要不同的数据进行训练和评估模型,是为了防止过拟合。当然,还有其他(稍微复杂一些的)交叉验证技术,例如实践中经常使用的k折交叉验证。
网格搜索是一种执行超参数优化的方法,即为给定模型(例如CNN)和测试数据集找到最佳超参数组合的方法(超参数的一个示例是优化器的学习率)。在此场景中,您有几个模型,每个模型具有不同的超参数组合。这些参数组合对应于单个模型的“网格”上的一个点。目标是训练每个模型并评估它们,例如使用交叉验证。然后选择表现最好的模型。
举个具体的例子,如果您正在使用支持向量机,则可以使用不同的gamma和C值。因此,例如,您可以使用以下值的网格来设置
网格搜索是一种执行超参数优化的方法,即为给定模型(例如CNN)和测试数据集找到最佳超参数组合的方法(超参数的一个示例是优化器的学习率)。在此场景中,您有几个模型,每个模型具有不同的超参数组合。这些参数组合对应于单个模型的“网格”上的一个点。目标是训练每个模型并评估它们,例如使用交叉验证。然后选择表现最好的模型。
举个具体的例子,如果您正在使用支持向量机,则可以使用不同的gamma和C值。因此,例如,您可以使用以下值的网格来设置
(gamma, C):(1, 1), (0.1, 1), (1, 10), (0.1, 10)。它是一个网格,因为它就像gamma的[1, 0.1]和C的[1, 10]之积。网格搜索基本上会为每个这四个(gamma, C)值对训练一个SVM,然后使用交叉验证进行评估,并选择表现最佳的那个。- Or Neeman
1
如果我已经完成了SearchGridCV并获得了所需的估计器,我是否需要再次运行cross_validate?cross_validate的结果是否与SearchGridCV的最佳估计器相同? - EBDS
20
交叉验证是一种稳健地估计模型测试集性能(泛化)的方法。网格搜索是一种选择由参数网格参数化的模型族中最佳模型的方法。
在这里,“模型”不仅指训练实例,还包括算法和参数,例如
在这里,“模型”不仅指训练实例,还包括算法和参数,例如
SVC(C=1, kernel='poly')。- Andreas Mueller
2
3我理解了。但在scikit-learn的示例中,首先通过执行
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.5,random_state = 0对数据集进行拆分,然后在网格搜索中有clf = GridSearchCV(SVC(C = 1),tuned_parameters,cv = 5,scoring = score)这是否意味着第一步将一个1000个训练集分成500个训练和500个测试对象,然后网格搜索将这500个对象分成“cv = 5” 5折交叉验证?因此,这500个对象被分成250和250,或400和100等等! - Linda11没错,一半的数据将被保留用于在网格搜索模型选择后进行评估(使用5倍交叉验证)。 这么做的原因不仅是为了选择最佳模型,还要对其泛化能力进行良好估计(即它在新数据上的表现如何)。 不能仅使用网格搜索交叉验证得分,因为您选择了在那个得分最高的模型,所以可能会存在某种选择偏差。 因此,在网格搜索结束后,他们保留部分数据进行测试。 - Or Neeman
15
交叉验证是指简单地将测试和训练数据分开,并使用测试数据验证训练结果。我知道两种交叉验证技术。
第一种是测试/训练交叉验证。将数据分割为测试和训练。
第二种是k折交叉验证,将数据分成k个容器,使用每个容器作为测试数据,其余数据作为训练数据并针对测试数据进行验证。重复这个过程k次,获取平均性能。k折交叉验证特别适用于小数据集,因为它最大化了测试和训练数据。
网格搜索是系统地遍历多个参数调整组合,对每个参数组合进行交叉验证并确定哪个组合提供了最佳性能。您可以通过微调参数来尝试许多组合。
- clockworks
0
交叉验证是一种保留数据集特定子集不参与训练模型的方法。稍后,在最终确定模型之前,您将在此子集上测试模型。
执行交叉验证的主要步骤如下:
1. 将整个数据集分为训练集和测试集(例如,整个数据集的80%是训练集,剩余的20%是测试集); 2. 使用训练数据集训练模型; 3. 在测试数据集上测试模型。如果模型在测试数据集上表现良好,则继续训练过程。
还有其他交叉验证方法,例如:
1. 留一法交叉验证(LOOCV); 2. K折交叉验证; 3. 分层K折交叉验证; 4. 对抗性交叉验证策略(用于训练和测试数据集差异很大的情况)。
执行交叉验证的主要步骤如下:
1. 将整个数据集分为训练集和测试集(例如,整个数据集的80%是训练集,剩余的20%是测试集); 2. 使用训练数据集训练模型; 3. 在测试数据集上测试模型。如果模型在测试数据集上表现良好,则继续训练过程。
还有其他交叉验证方法,例如:
1. 留一法交叉验证(LOOCV); 2. K折交叉验证; 3. 分层K折交叉验证; 4. 对抗性交叉验证策略(用于训练和测试数据集差异很大的情况)。
- CodeMaster GoGo
1
5这并没有回答原来的问题。您没有解释交叉验证和网格搜索之间的区别。 - nbro
0
在进行(监督式)机器学习实验时,通常会将可用数据的一部分作为测试集X_test,y_test(您可以决定多少,大多数情况下在20-30%之间)。在交叉验证中,您使用不同的训练集运行几次:
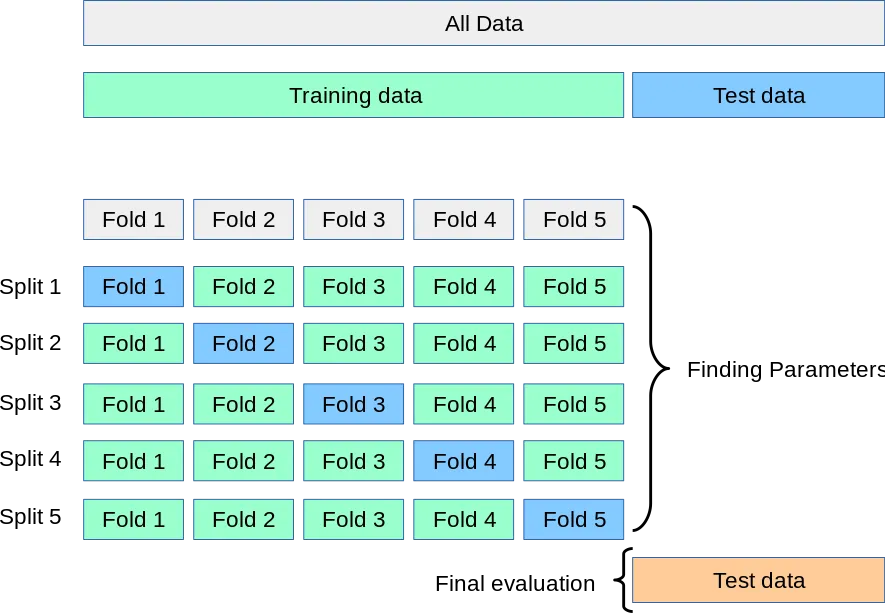 因此,在这种情况下,您运行5倍交叉验证(5次运行),并且在每个Fold中,您都会选择一个不同的训练集(
因此,在这种情况下,您运行5倍交叉验证(5次运行),并且在每个Fold中,您都会选择一个不同的训练集(X_train,y_train)。测试数据始终是保留的。这用于避免过度拟合,即避免模型针对一个特定问题进行训练,但当新数据到达时,它将无法给出良好的结果。
最佳参数可以通过网格搜索技术确定。大多数机器学习模型都有可能调整参数以找到最佳结果,例如在决策树中,您可以在参数列表中调整节点数。
通常情况下,如果您想开发一个好的机器学习模型,您会使用两种技术的组合:交叉验证和网格搜索。- PV8
-11
简单来说,把制作意大利面比作建立一个模型:
- 交叉验证 - 选择意大利面的数量
- 网格搜索 - 选择正确的配料比例。
- Dinesh Varma Indukuri
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接