给定一张有向图,每个节点都有一个权重。从任意节点A开始,存在一组可以到达的节点。定义SUM为这个集合的总权重。
问题: 如何高效地计算该图中每个节点的SUM?该图可能包含数百万个节点。
更新1: 图数据结构由起始节点集合组成,每个节点都有一个指向其他节点的集合。
我尝试过: 递归计算每个节点的后代,并根据后代集合计算SUM。但是这种递归非常低效,因为我必须进行大量的集合并、迭代操作。此外,我尝试在每个节点缓存后代集合。然而,它很容易耗尽内存。
更新2: 示例图,边都是有向的,上层节点指向下层节点。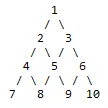 结果应为:
SUM(1)=55
SUM(2)=35
SUM(3)=41
SUM(4)=19
SUM(5)=22
SUM(6)=25
...
结果应为:
SUM(1)=55
SUM(2)=35
SUM(3)=41
SUM(4)=19
SUM(5)=22
SUM(6)=25
...
问题: 如何高效地计算该图中每个节点的SUM?该图可能包含数百万个节点。
更新1: 图数据结构由起始节点集合组成,每个节点都有一个指向其他节点的集合。
我尝试过: 递归计算每个节点的后代,并根据后代集合计算SUM。但是这种递归非常低效,因为我必须进行大量的集合并、迭代操作。此外,我尝试在每个节点缓存后代集合。然而,它很容易耗尽内存。
更新2: 示例图,边都是有向的,上层节点指向下层节点。
结果应为:
SUM(1)=55
SUM(2)=35
SUM(3)=41
SUM(4)=19
SUM(5)=22
SUM(6)=25
...