我遇到了一个问题,即在匹配包含特殊字符的数据框和不包含特殊字符的数据框时无法匹配。例如:Doña Ana County与Dona Ana County。
以下是一个脚本,您可以使用它重现输出:
library(tidyverse)
library(acs)
tbl_df(acs::fips.place) # contains "Do\xf1a Ana County"
tbl_df(tigris::fips_codes) # contains "Dona Ana County"
例子:
tbl_df(tigris::fips_codes) %>% filter(county == "Dona Ana County")
返回:
# A tibble: 1 x 5
state state_code state_name county_code county
<chr> <chr> <chr> <chr> <chr>
1 NM 35 New Mexico 013 Dona Ana County
很遗憾,以下查询未返回任何结果:
tbl_df(acs::fips.place) %>% filter(COUNTY == "Do\xf1a Ana County")
tbl_df(acs::fips.place) %>% filter(COUNTY == "Doña Ana County")
tbl_df(acs::fips.place) %>% filter(COUNTY == "Dona Ana County")
# A tibble: 0 x 7
# ... with 7 variables: STATE <chr>, STATEFP <int>, PLACEFP <int>, PLACENAME <chr>, TYPE <chr>, FUNCSTAT <chr>, COUNTY <chr>
然而,在R Studio中打开数据框时,它显示:
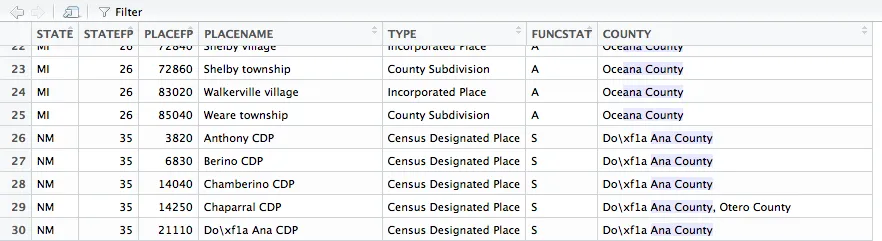
acs::fips.place的编码已经损坏,\\xf1a并没有意义;\xf1a有(在latin1编码下),但是从一个编码转换到另一个编码是困难的。如果我是你,我会向acs包的维护者报告一个 bug。 - Ista