以下是三种方法:
library(lubridate)
library(xts)
library(dplyr)
library(forecast)
df$Date = mdy(df$Date)
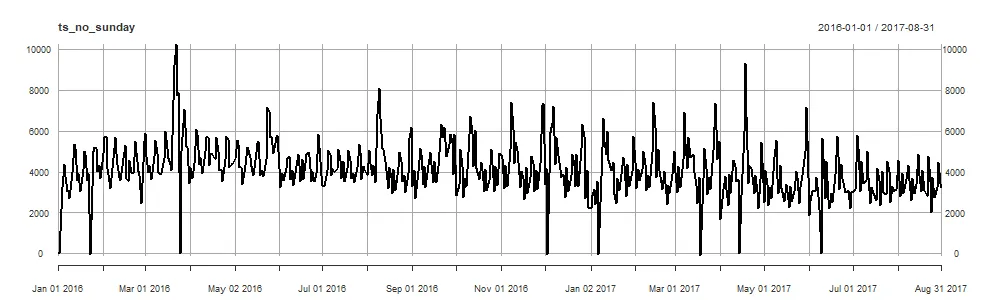
去除星期天:
ts_no_sunday = df %>%
filter(wday(df$Date) != 1) %>%
{xts(.$Units, .$Date)}
plot(ts_no_sunday)
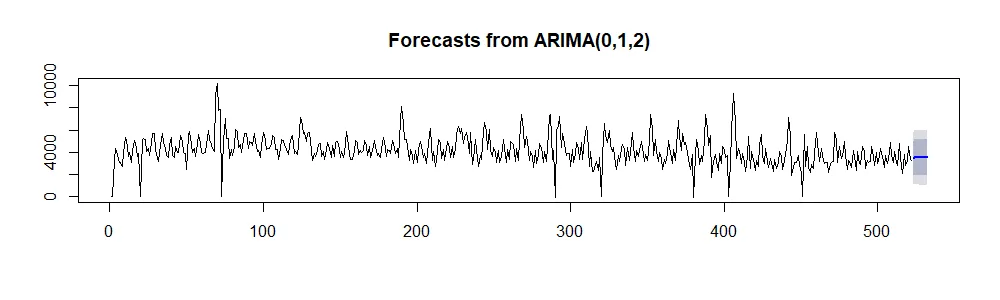
no_sunday_arima = auto.arima(ts_no_sunday)
plot(forecast(no_sunday_arima, h = 10))
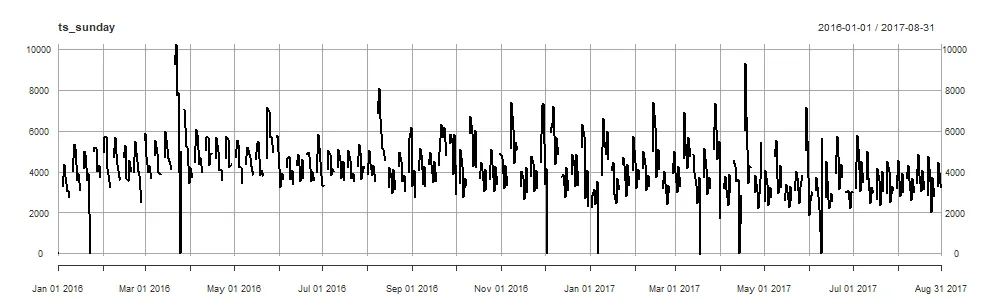
将周日替换为NA:
ts_sunday = df
mutate(Units = replace(Units, which(wday(df$Date) == 1), NA))
{xts(.$Units, .$Date)}
plot(ts_sunday)
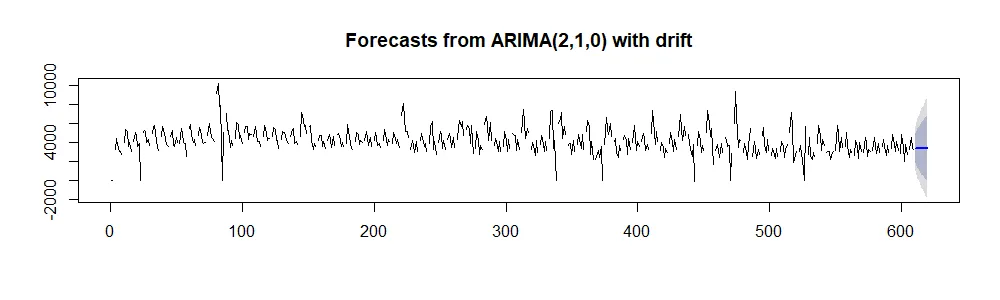
sunday_arima = auto.arima(ts_sunday)
plot(forecast(sunday_arima, h = 10))
插值星期日:
ts_interp = df %>%
mutate(Units = replace(Units, which(wday(df$Date) == 1), NA),
Units = na.approx(Units)) %>%
{xts(.$Units, .$Date)}
plot(ts_interp)
interp_arima = auto.arima(ts_interp)
plot(forecast(interp_arima, h = 10))

注意事项:
正如你所看到的,它们产生不同的预测结果。这是因为第一个时间序列是不规则的,第二个是带有缺失值的常规时间序列,第三个是带有插值数据的常规时间序列。在我看来,处理缺失值的更好方法是在拟合ARIMA之前进行插值,因为ARIMA假定时间序列是等间隔的。然而,这也取决于您的“缺失”数据点是否实际缺失,而不是活动停止。前者应该用插值处理,而对于后者,您可能最好删除星期天,并将时间序列视为不存在星期天。
请参见如何处理不存在或缺失的数据?上的讨论,
以及使用R预测包处理缺失值和/或不规则时间序列上的讨论。
df相同名称的其他对象的代码。尝试清除你的工作空间,然后只重新运行你的数据和我的代码。你也可以使用test = mdy(df$Date)进行测试,这样每次运行代码时就不会替换df$Date。 - acylam