我正在尝试使用Metal进行一些GPGPU计算。我有一个基本的Metal管道,其中:
- 创建所需的MTLComputePipelineState管道和所有相关对象(MTLComputeCommandEncoder、命令队列等); - 创建一个目标纹理以进行写入(使用desc.usage = MTLTextureUsageShaderWrite;); - 启动一个基本着色器来用一些值填充这个纹理(在我的实验中,要么将颜色分量之一设置为1,要么根据线程坐标创建一个灰度梯度); - 从GPU读回此纹理的内容。
我在两个环境中测试这个代码:
- 在OSX 10.11上,使用MacBook Pro early 2013; - 在iOS 9上,使用iPhone 6。
iOS版本可以正常运行,并且我得到了我要求着色器执行的结果。但是,在OSX上,我得到了一个有效的(非nil,大小正确)输出纹理。然而,当获取数据时,我得到的只是0。
我是否错过了与OS X实现特定的步骤?这似乎发生在NVIDIA GT650M和Intel HD4000上,或者可能是运行时中的错误?
由于我目前不知道如何进一步调查此问题,因此在此方面的任何帮助也将不胜感激:-)
编辑 - 我当前的实现
这是我的实现的初始(失败)状态。这是一个有点冗长,但主要是用于创建管道的样板代码:
- 创建所需的MTLComputePipelineState管道和所有相关对象(MTLComputeCommandEncoder、命令队列等); - 创建一个目标纹理以进行写入(使用desc.usage = MTLTextureUsageShaderWrite;); - 启动一个基本着色器来用一些值填充这个纹理(在我的实验中,要么将颜色分量之一设置为1,要么根据线程坐标创建一个灰度梯度); - 从GPU读回此纹理的内容。
我在两个环境中测试这个代码:
- 在OSX 10.11上,使用MacBook Pro early 2013; - 在iOS 9上,使用iPhone 6。
iOS版本可以正常运行,并且我得到了我要求着色器执行的结果。但是,在OSX上,我得到了一个有效的(非nil,大小正确)输出纹理。然而,当获取数据时,我得到的只是0。
我是否错过了与OS X实现特定的步骤?这似乎发生在NVIDIA GT650M和Intel HD4000上,或者可能是运行时中的错误?
由于我目前不知道如何进一步调查此问题,因此在此方面的任何帮助也将不胜感激:-)
编辑 - 我当前的实现
这是我的实现的初始(失败)状态。这是一个有点冗长,但主要是用于创建管道的样板代码:
id<MTLDevice> device = MTLCreateSystemDefaultDevice();
id<MTLLibrary> library = [device newDefaultLibrary];
id<MTLCommandQueue> commandQueue = [device newCommandQueue];
NSError *error = nil;
id<MTLComputePipelineState> pipeline = [device newComputePipelineStateWithFunction:[library
newFunctionWithName:@"dummy"]
error:&error];
if (error)
{
NSLog(@"%@", [error localizedDescription]);
}
MTLTextureDescriptor *desc = [MTLTextureDescriptor texture2DDescriptorWithPixelFormat:MTLPixelFormatRGBA8Unorm
width:16
height:1
mipmapped:NO];
desc.usage = MTLTextureUsageShaderWrite;
id<MTLTexture> texture = [device newTextureWithDescriptor:desc];
MTLSize threadGroupCounts = MTLSizeMake(8, 1, 1);
MTLSize threadGroups = MTLSizeMake([texture width] / threadGroupCounts.width,
[texture height] / threadGroupCounts.height,
1);
id<MTLCommandBuffer> commandBuffer = [commandQueue commandBuffer];
id<MTLComputeCommandEncoder> commandEncoder = [commandBuffer computeCommandEncoder];
[commandEncoder setComputePipelineState:pipeline];
[commandEncoder setTexture:texture atIndex:0];
[commandEncoder dispatchThreadgroups:threadGroups threadsPerThreadgroup:threadGroupCounts];
[commandEncoder endEncoding];
[commandBuffer commit];
[commandBuffer waitUntilCompleted];
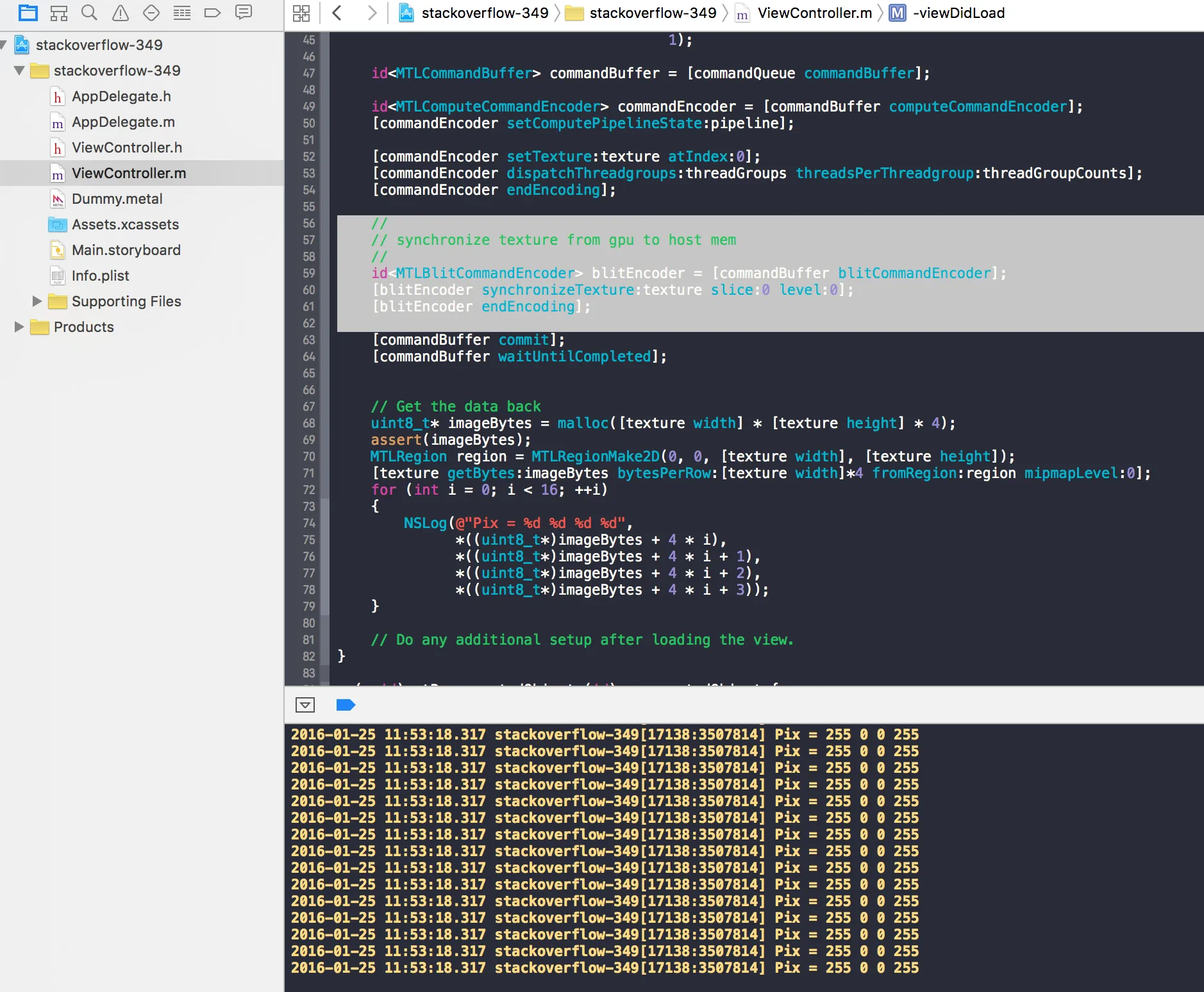
用于获取数据的代码如下(我将文件分成两部分以获得更小的代码块):
// Get the data back
uint8_t* imageBytes = malloc([texture width] * [texture height] * 4);
assert(imageBytes);
MTLRegion region = MTLRegionMake2D(0, 0, [texture width], [texture height]);
[texture getBytes:imageBytes bytesPerRow:[texture width]*4 fromRegion:region mipmapLevel:0];
for (int i = 0; i < 16; ++i)
{
NSLog(@"Pix = %d %d %d %d",
*((uint8_t*)imageBytes + 4 * i),
*((uint8_t*)imageBytes + 4 * i + 1),
*((uint8_t*)imageBytes + 4 * i + 2),
*((uint8_t*)imageBytes + 4 * i + 3));
}
这是着色器代码(将1写入红色和alpha通道,在主机上读取时应该变成0xff):
#include <metal_stdlib>
using namespace metal;
kernel void dummy(texture2d<float, access::write> outTexture [[ texture(0) ]],
uint2 gid [[ thread_position_in_grid ]])
{
outTexture.write(float4(1.0, 0.0, 0.0, 1.0), gid);
}