我有以下表格:
dbPratiche :
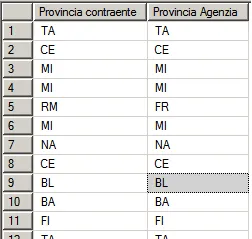
我想要以不同的 [Provincia contraente](第一列)排列,并计算该 [Provincia contraente] 出现在 [Provincia Agenzia] 中的次数。
例如:
如果我使用以下查询将第一列排列为不同值:
select distinct([Provincia contraente]) from dbPratiche
接下来想在下一列中给出它到达第二列[Provincia Agenzia]的次数。
简单来说,原型查询:
SELECT DISTINCT( [provincia contraente] ),
Count([provincia agenzia])
FROM dbpratiche
WHERE Distinct([provincia contraente]) = [provincia agenzia]
当然,这个查询会失败,但我使用连接进行了第二个查询,如下所示:
SELECT DISTINCT( p1.[provincia contraente] ) AS 'PC',
Count(p2.[provincia agenzia])
FROM dbpratiche p1
INNER JOIN dbpratiche p2
ON p1.[provincia contraente] = p2.[provincia contraente]
AND p2.[provincia agenzia] = p1.[provincia contraente]
GROUP BY p1.[provincia contraente]
但是没有给我正确的结果。
请帮帮我。
实际表格:
Provincia contraente | Provincia Agenzia
TA TA
CE TA
CE CE
MI FR
MI TA
FR FR
期望的结果:
Provincia contraente | Provincia Agenzia
TA 3
CE 1
MI 0
FR 2
编辑2:
还想添加第一列的计数
Provincia contraente | Provincia Agenzia | cnt Provincia contraente
TA 3 1
CE 1 2
MI 0 2
FR 2 1
我尝试过:
我按照@verex的查询方法添加了COUNT(dbPratiche.[Provincia contraente]),代码如下:
SELECT T1.[provincia contraente],
Count(dbpratiche.[provincia agenzia]),
Count(dbpratiche.[provincia contraente])
FROM dbpratiche
RIGHT JOIN (SELECT DISTINCT [provincia contraente]
FROM dbpratiche) AS T1
ON dbpratiche.[provincia agenzia] = T1.[provincia contraente]
GROUP BY T1.[provincia contraente]
但是我得到了[Provincia Agenzia]的数量。
请帮忙。